
TEI Lite�i TEI U5 �j �̃���
(1998.8.)
�@�@�P�@�͂��߂� �@�@12�@���X�g �@�@�Q�@�ȒP�ȗ� �@�@13�@�����I���p �@�@�R�@�e�L�X�g�̍\�� �@�@14�@�e�[�u���i�\�j �@�@�S�@�{���̃}�[�N�A�b�v �@�@15�@�}�ƊG �@�@�T�@�y�[�W�ԍ��E�s�ԍ� �@�@16�@���߁E���� �@�@�U�@���̋��� �@�@17�@�Z�p���� �@�@�V�@���L �@�@18�@�����R�[�h�A�� �@�@�W�@���ݎQ�Ƃƃ����N �@�@19�@�O���E��t �@�@�X�@�ҏW�̂��߂̏��u �@�@20�@TEI �w�b�_ �@�@10�@�ȗ��E�폜�E�t�� �@�@21�@�v�f���X�g �@�@11�@���O�E���t�E���l�E���� �@�@22�@���t�@�����X
TEI Lite�iTEI U 5�j
1995.6
http://www.uic.edu/orgs/tei/intros/teiu5.tei
http://www.uic.edu/orgs/tei/intros/teiu5.split.html
�y�Q�Ɓz
- TEI �iTEI document P3, Guidelines for Electronic Text Encoding and Interchange, published in Chicago and Oxford in May 1994�j
http://www-tei.uic.edu/orgs/tei/intros/teiu5.tei
ftp://info.ox.ac.uk/pub/ota/TEI/doc/teiu5.tei
http://www-tei.uic.edu/orgs/tei/intros/teiu5.html
http://info.ox.ac.uk/~archive/teilite/teiu5.html
- DTD �iteilite.dtd�j
http://www-tei.uic.edu/orgs/tei/p3/dtd/teilite.dtd
ftp://ftp-tei.uic.edu/pub/tei/lite/teilite.dtd
ftp://info.ox.ac.uk/pub/ota/TEI/dtd/teilite.dtd
�P�@�͂��߂�
TEI �K�C�h���C���i TEI P3�A1994.5�j�́A�ȉ��̂悤�ȓ���������Ă���B- ���l�ȕ��͂ɋ��ʂ��鍪�{�I���������L����B
- �K�v�ɉ����Đ��I�ȓ�����e�Ղɕt���i�����j�ł���B
- ��̓����ɑ��ē����ɑ��l�ȃ}�[�N�A�b�v���\�ł���B
- ���[�U�[��`�ɂ��}�[�N�A�b�v���\�ł���B
- �e�L�X�g�ƃ}�[�N�A�b�v�ɂ��ēK�ȉ�����s����B
- TEI �̊j�ƂȂ�^�O�Z�b�g���قږԗ�����B
- ���l�ȕ����ɓK�ɑΉ��ł���B�ithe Oxford Text Archive �̗�j
- �����̕����̏��������łȂ��A�����쐬�ɂ��g����B
- �L�͂� SGML �Ή��\�t�g�E�F�A�𗘗p�ł���B
- TEI �̊g���@�\�ɂ��A TEI DTD �����p�������́i���S�Ȍ݊����j�B
- �Ȃ����y�ʁE�ȕւł��邱�ƁB
The Oxford Text Archive �͓Ǝ��}�[�N�A�b�v���� SGML �ɕϊ�����̂� TEI Lite ���g���Ă���B���@�[�W�j�A�B����w�E�~�V�K���B����w�̓d�q�e�L�X�g�Z���^�[�������̃}�[�N�A�b�v�� TEI Lite �ōs���Ă���B TEI �ithe Text Encoding Initiative�j���g���{�����܂ދZ�p������ TEI Lite �ɏ]���č쐬���Ă���B
�Q�@�ȒP�ȗ�
�����̑̍قɒ����ł��邱�Ƃ�����ڎw�����}�[�N�A�b�v�̗�B�|(1)�����A(2)���̃}�[�N�t���B
(1)
CHAPTER 38
READER, I married him. A quiet wedding we had: he and I, the par-
son and clerk, were alone present. When we got back from church, I
went into the kitchen of the manor-house, where Mary was cooking
the dinner, and John cleaning the knives, and I said --
'Mary, I have been married to Mr Rochester this morning.' The
housekeeper and her husband were of that decent, phlegmatic
order of people, to whom one may at any time safely communicate a
remarkable piece of news without incurring the danger of having
one's ears pierced by some shrill ejaculation and subsequently stunned
by a torrent of wordy wonderment. Mary did look up, and she did
stare at me; the ladle with which she was basting a pair of chickens
roasting at the fire, did for some three minutes hang suspended in air,
and for the same space of time John's knives also had rest from the
polishing process; but Mary, bending again over the roast, said only --
'Have you, miss? Well, for sure!'
A short time after she pursued, 'I seed you go out with the master,
but I didn't know you were gone to church to be wed'; and she
basted away. John, when I turned to him, was grinning from ear to
ear.
'I telled Mary how it would be,' he said: 'I knew what Mr Ed-
ward' (John was an old servant, and had known his master when he
was the cadet of the house, therefore he often gave him his Christian
name) -- 'I knew what Mr Edward would do; and I was certain he
would not wait long either: and he's done right, for aught I know. I
wish you joy, miss!' and he politely pulled his forelock.
'Thank you, John. Mr Rochester told me to give you and Marythis.'
I put into his hand a five-pound note. Without waiting to hear
more, I left the kitchen. In passing the door of that sanctum some time
after, I caught the words --
'She'll happen do better for him nor ony o' t' grand ladies.' And
again, 'If she ben't one o' th' handsomest, she's noan faa\l, and varry
good-natured; and i' his een she's fair beautiful, onybody may seethat.'
I wrote to Moor House and to Cambridge immediately, to say what
I had done: fully explaining also why I had thus acted. Diana and
474
JANE EYRE 475
Mary approved the step unreservedly. Diana announced that she
would just give me time to get over the honeymoon, and then she
would come and see me.
'She had better not wait till then, Jane,' said Mr Rochester, when I
read her letter to him; 'if she does, she will be too late, for our honey-
moon will shine our life long: its beams will only fade over your
grave or mine.'
How St John received the news I don't know: he never answered
the letter in which I communicated it: yet six months after he wrote
to me, without, however, mentioning Mr Rochester's name or allud-
ing to my marriage. His letter was then calm, and though very serious,
kind. He has maintained a regular, though not very frequent correspond-
ence ever since: he hopes I am happy, and trusts I am not of those who
live without God in the world, and only mind earthly things.
(2)
<pb n='474'>
<div1 type=chapter n='38'>
<p>Reader, I married him. A quiet wedding we had: he and I,
the parson and clerk, were alone present. When we got back
from church, I went into the kitchen of the manor-house,
where Mary was cooking the dinner, and John cleaning the
knives, and I said ‐
<p><q>Mary, I have been married to Mr Rochester this
morning.</q> The housekeeper and her husband were of that
decent, phlegmatic order of people, to whom one may at any
time safely communicate a remarkable piece of news without
incurring the danger of having one's ears pierced by some
shrill ejaculation and subsequently stunned by a torrent of
wordy wonderment. Mary did look up, and she did stare at
me; the ladle with which she was basting a pair of chickens
roasting at the fire, did for some three minutes hang
suspended in air, and for the same space of time John's
knives also had rest from the polishing process; but Mary,
bending again over the roast, said only ‐
<p><q>Have you, miss? Well, for sure!</q>
<p>A short time after she pursued, <q>I seed you go out with
the master, but I didn't know you were gone to church to be
wed</q>; and she basted away. John, when I turned to him,
was grinning from ear to ear. <q>I telled Mary how it would
be,</q> he said: <q>I knew what Mr Edward</q> (John was an
old servant, and had known his master when he was the cadet
of the house, therefore he often gave him his Christian
name) ‐ <q>I knew what Mr Edward would do; and I was
certain he would not wait long either: and he's done right,
for aught I know. I wish you joy, miss!</q> and he politely
pulled his forelock.
<p><q>Thank you, John. Mr Rochester told me to give you and
Mary this.</q>
<p>I put into his hand a five-pound note. Without waiting
to hear more, I left the kitchen. In passing the door of
that sanctum some time after, I caught the words ‐
<p><q>She'll happen do better for him nor ony o' t' grand
ladies.</q> And again, <q>If she ben't one o' th'
handsomest, she's noan faàl, and varry good-natured;
and i' his een she's fair beautiful, onybody may see
that.</q>
<p>I wrote to Moor House and to Cambridge immediately, to
say what I had done: fully explaining also why I had thus
acted. Diana and <pb n='475'> Mary approved the step
unreservedly. Diana announced that she would just give me
time to get over the honeymoon, and then she would come and
see me.
<p><q>She had better not wait till then, Jane,</q> said Mr
Rochester, when I read her letter to him; <q>if she does,
she will be too late, for our honeymoon will shine our life
long: its beams will only fade over your grave or mine.</q>
<p>How St John received the news I don't know: he never
answered the letter in which I communicated it: yet six
months after he wrote to me, without, however, mentioning Mr
Rochester's name or alluding to my marriage. His letter was
then calm, and though very serious, kind. He has maintained
a regular, though not very frequent correspondence ever
since: he hopes I am happy, and trusts I am not of those who
live without God in the world, and only mind earthly things.
���̎ʂ��ɂ́A���������_������B
- �e�L�X�g�{���ƃy�[�W�A�w�b�_�Ȃǂ̋�ʂ��Ȃ��B
- �A�|�X�g���t�ƈ��p���̋�ʂ��Ȃ��B
- �n�C�t�l�[�V�����̖��Ӗ��ȕۑ��B
- �A�N�Z���g������_�b�V�������̎��X�̂����ŏ������Ă��܂��B
- �i���̋敪�������ōs���A�e�s���ɉ��s���������邽�߁A�t�H�[�}�b�g�̕ύX�������Ȃ��B
TEI �������g�����Ƃɂ���āA���̂悤�ȋ�ʂ��͂����肷��B
- �i���̋敪�B
- �A�|�X�g���t�ƈ��p���̋�ʁB
- �A�N�Z���g��_�b�V���ɂ̓G���e�B�e�B�Q�Ƃ��g���̂ŏ�Ɉ��ł���B
- �y�[�W�̋敪�͋�v�f�����Ŏ����A���C�A�E�g�ɉe�����Ȃ��B
�@�@�|<pb>�ipage break�j - �����̉��s�ʒu��n�C�t�l�[�V�����́A���ʂȏꍇ�̂݃}�[�N����B
�@�@�|�����Ȃǂ̏ꍇ�B - �i���͂��߂͉��s���邪�A�C���f���g�͍s��Ȃ��B
TEI �����ł́A���̂悤�ȃ}�[�N�A�b�v���\�ł���B
- �����̒�����t�^
- �r���̕t��
- �����N�̂��߂̃|�C���^�̕t��
- �������̂̎���
- �����I�����̓���
- ���@�I���́i���ރR�[�h�j�̕t�^
- �n�̕��Ɖ�b�̋敪
- �e�L�X�g�̕��́E���߂̃^�O�t��
- �摜�E�������Ƃ̃����N
���ɂ��A�傫�ȉ\��������B���̈��B�i TEI P3 ���Q�ƁB�j
- ��b�W
- ��i���T
- �����I���
�R�@�e�L�X�g�̍\��
TEI �����̃e�L�X�g�ɂ� TEI header (<teiHeader>...</teiHeader>) ��t����B�w�b�_�́A�@�t�@�C�����A�A�}�[�N�A�b�v���A�B�������A�C�X�V�������琬��B�i�u20�v���Q�ƁB�j
�e�L�X�g�͒P�Ƃ̍�i�̏ꍇ������A���؏W�̂悤�ɕ����̍�i���琬��ꍇ������B
�P�Ƃ̍�i�̍\���́A���̌`�ɂ܂Ƃ߂��邾�낤�B
<TEI.2>
<teiHeader> [ TEI Header information ] </teiHeader>
<text>
<front> [ front matter ... ] </front>
<body> [ body of text ... ] </body>
<back> [ back matter ... ] </back>
</text>
</TEI.2>
�����e�L�X�g�̖{���́A�O���[�v�ɕ�����A���ꂼ��ɑO���E��t���������B
<TEI.2>
<teiHeader> [ header information for the composite ] </teiHeader>
<text>
<front> [ front matter for the composite ] </front>
<group>
<text>
<front> [ front matter of first text ] </front>
<body> [ body of first text ] </body>
<back> [ back matter of first text ] </back>
</text>
<text>
<front> [ front matter of second text] </front>
<body> [ body of second text ] </body>
<back> [ back matter of second text ] </back>
</text>
[ more texts or groups of texts here ]
</group>
<back> [ back matter for the composite ] </back>
</text>
</TEI.2>
�X�̃e�L�X�g�Ƀw�b�_�����A��`��ʂɂ��邱�Ƃ��ł���B�i TEI �R�[�p�X�j�������A�R�[�p�X�̕����̂��P�̃I�u�W�F�N�g�Ƃ��Ĉ������Ƃ́A���݂� TEI �ł͂ł��Ȃ��B
<teiCorpus>
<teiHeader> [header information for the corpus]</teiHeader>
<TEI.2>
<teiHeader>[header information for first text]</teiHeader>
<text> [first text in corpus] </text>
</TEI.2>
<TEI.2>
<teiHeader>[header information for second text]</teiHeader>
<text> [second text in corpus] </text>
</TEI.2>
</teiCorpus>
�S�@�{���̃}�[�N�A�b�v
TEI �����̗v�f
- <front>
- �O�u���i�w�b�_�A�^�C�g���E�y�[�W�A�����A�����A���j
- <group>
- �P�Ƃ̍�i�̃O���[�v�i����q�ɂ��ł���B�j
- <body>
- ��i�{��
- <back>
- �㏑���i�t�^�j
�O���E��t���̗v�f�ɂ��ẮA�u19�v���Q�ƁB
�e�L�X�g�敪�v�f
�e�L�X�g�͌X�̒i���i<p>�j�A���͏͐ߍ��Ȃǂ̋敪�ɕ�����B�i�@���ׂ�<div>�A���͇A�i�K�ɉ�����<div1>����<div7>�܂ł̋敪�����B����ȏ�̋敪������ꍇ�͇@�ɂ���ď��߂��炽����<div>���l�X�g������悢�B�j
<p>�^<divX>�̑����F id �� n �́A�ǂ̗v�f�ɂ��g���鋤�ʑ����ł���B
- type
- Book, Chapter, Poem ���B�����͉��ʂ̋敪�Ɍp�������B
- id
- �B�ꐫ�������ʒl�B���ݎQ�ƁiCross References�j ����N�i�u�W�v���Q�ƁB�j�ɗ��p�ł���B
- n
- �Z�����O�␔�������������B
id �ɂ���ĕ����̊K�w�\���f�����B�i�A�_���E�X�~�X�̍��x�_ Wealth of Nations �̏͐ߍ��������B�j
<div1 id=WN1 n='I' type='book'>
<div2 id=WN101 n='I.1' type='chapter'>... </div2>
<div2 id=WN102 n='I.2' type='chapter'>... </div2>
...
<div2 id=WN110 n='I.10' type='chapter'>
<div3 id=WN1101 n='I.10.1' type=part>... </div3>
<div3 id=WN1102 n='I.10.2' type=part>... </div3>
</div2>
...
</div1>
<div1 id=WN2 n='II' type='book'>
....
</div1>
...
�����̏����ŏ͂��ʂ��ԍ��ŐU���Ă���ꍇ�̃^�O�t����B�i�͔ԍ��� n �����ŕ\���A id �����ɂ���đ扽���扽�͂ł��邩�������B�j
<div1 id=TS01 n='1' type='Volume'>
<div2 id=TS011 n='1' type='Chapter'>
...
<div2 id=TS012 n='2'>
...
</div1>
<div1 id=TS02 n='2' type='Volume'>
<div2 id=TS021 n='3'type='Chapter'>
...
<div2 id=TS022 n='4'>
...
</div1>
���o���ƏI��茩�o��
�^�O�̏ڍׂ́A�u19�v���Q�ƁB
- <head>
- ���o���i�߂̏���A���X�g��p��W�̑薼���j
- <trailer>
- �I��茩�o���i����ɗނ���t�b�^�Ȃǁj
���o�����v�f�⑮���ŕ\����A�����̃^�O�͕K�v�Ȃ��B���̕��@�ł͍Č��ł��Ȃ��ꍇ�ȂǂɊ��p����B�i�g�}�X�E�n�[�f�B�� Under the Greenwood Tree �̖`���̗�B�j
<div1 id=UGT1 n='Winter' type='Part'> <div2 id=UGT11 n='1' type='Chapter'> <head>Mellstock-Lane</head> <p>To dwellers in a wood almost every species of tree ...
�U���E�C���E�Y��
���ɉC����Y�ȁE�r�{���ɗp����^�O�B
- <l>
- �C���̂P�s�B
- part ����
- Y �C���ʂŕs���S�ȍs�B N ���S�ȍs�B I(initial) ���߂̕����̒f�ЁB M(medial) ���Ԃ̕����B F(final) �I���̕����B
- <lg>
- �C���̂܂Ƃ܂�i�X�^���U�A���t���C���A�A�A���j�B
- <sp>
- �l���̉�b�ł��邱�Ƃ������B�i�r�{�E�U���E�C�����j
- who ����
- ID �����A�l�������ʁE���肷��B
- <speaker>
- �r�{��f�Ђ̘b����i�P���E�����j�̖����L�������x���B
- <stage>
- �g�����p�̃^�O�B����w�����s���B
- type ����
- entrance, exit, setting, delivery ���B�w���̎�ނ������B
�^�O�t���̎���B�����ُ̍�̍s��ێ�����Ȃ�A <lb> �v�f���g���B�i�u�T�v���Q�ƁB�j
<lg n=I>
<l>I Sing the progresse of a
deathlesse soule,</l>
<l>Whom Fate, with God made,
but doth not controule,</l>
<l>Plac'd in most shapes; all times
before the law</l>
<l>Yoak'd us, and when, and since,
in this I sing.</l>
<l>And the great world to his aged evening;</l>
<l>From infant morne, through manly noone I draw.</l>
<l>What the gold Chaldee, of silver Persian saw,</l>
<l>Greeke brass, or Roman iron, is in this one;</l>
<l>A worke t'out weare Seths pillars, bricke and stone,</l>
<l>And (holy writs excepted) made to yeeld to none,</l>
</lg>
�Y�ȂȂǂŗL�C�����b����ɂ�蕪���Č����ꍇ�A part �����ł��ꂪ�f�Ђł��邱�Ƃ�����̂��ȒP�ł���B�P�̃X�^���U���Q�l�ŕ����ĉ̂��ꍇ�Ȃǂɂ����p�ł���B
<div1 type ='Act' n='I'><head>ACT I</head> <div2 type ='Scene' n='1'><head>SCENE I</head> <stage rend=italic> Enter Barnardo and Francisco, two Sentinels, at several doors</stage> <sp><speaker>Barn<l part=Y>Who's there? <sp><speaker>Fran<l>Nay, answer me. Stand and unfold yourself. <sp><speaker>Barn<l part=i>Long live the King! <sp><speaker>Fran<l part=m>Barnardo? <sp><speaker>Barn<l part=f>He. <sp><speaker>Fran<l>You come most carefully upon your hour.
rend �����ɂ��ẮA�u�U�v���Q�ƁB
<sp><speaker>First voice</speaker> <lg type=stanza part=I> <l>But why drives on that ship so fast <l>Withouten wave or wind? </lg> <sp><speaker>Second Voice</speaker> <lg part=F> <l>The air is cut away before. <l>And closes from behind. </lg>
�U���̉�b�ł��A�}�[�N�A�b�v���@�͓��l�ł���B who �����ʼn�b�̎����肷�邱�Ƃ��ł���B
<sp who=OPI><speaker>The reverend Doctor Opimiam</speaker> <p>I do not think I have named a single unpresentable fish. <sp who=GRM><speaker>Mr Gryll</speaker> <p>Bream, Doctor: there is not much to be said for bream. <sp who=OPI><speaker>The Reverend Doctor Opimiam</speaker> <p>On the contrary, sir, I think there is much to be said for him. In the first place.... <p>Fish, Miss Gryll -- I could discourse to you on fish by the hour: but for the present I will forbear... </sp>
�T�@�y�[�W�ԍ��E�s�ԍ�
���y�[�W�Ɖ��s�́A���̋�v�f�Ŏ����B
- <pb>(page break)
- ���y�[�W
- <lb>(line break)
- ���s�i�s�̊J�n�������B�j
�Ƃ��� n �������g����ق��A ed �����ɂ���ĔŐ��i�����j���������Ƃ��ł���B�i�łɂ��y�[�W���̑���������B�j�Ȃ��A�s���̃n�C�t�l�[�V�����̈����͈�l��v����B
<p>I wrote to Moor House and to Cambridge immediately, to say what I had done: fully explaining also why I had thus acted. Diana and <pb ed=ED1 n='475'> Mary approved the step unreservedly. Diana announced that she would <pb ed=ED2 n='485'>just give me time to get over the honeymoon, and then she would come and see me.
�����̗v�f�́A�e�L�X�g���̎Q�ƈʒu������ <milestone> �v�f�̓��ʂȃP�[�X�ł���B������́A���Z�N�V�����̊J�n�Ȃǂ������A�O�L ed �����̂ق��A unit �����i�Z�N�V�����̎�ނ������j���g����B�ł�Z�N�V�����̎�ނ� TEI �w�b�_�ɖ��L���Ă������ƁB�܂��A <pb> �A <lb> �� <milestone> �Ƃ͏���ɍ��p���ׂ��łȂ��B
�U�@���̋���
�t�H���g�̕ύX
�������̓t�H���g��O���t�A�F���̕ύX�ɂ���ēǎ҂̒��ӂ����N����B
���ʑ��� rend (rendition) �ɂ���ċ����̎d���������B�i rend='Bold'�A rend='Italic' ���j <hi> (hilight) �́A���ꎩ�̂ł͋����̎�ނ���肵�Ȃ��B
<hi rend=gothic>And this Indenture further witnesseth</hi> that the said <hi rend=italic>Walter Shandy</hi>, merchant, in consideration of the said intended marriage ...
�����̗��R���ł���ꍇ�A�ȉ��̂悤�ȗv�f���g����B
- <emph>
- ���@�I�A�C���I�Ȍ��ʂ̂��߂̋����B
- <foreign>
- �O����i�{���ƈقȂ錾��j
- <mentioned>
- ���y���
- <term>
- ���p��
- <title>
- �W��i��i�E�L���E�����E�G���E�p�����j
- lebel ����
- �^�C�g���̃��x���������B m (monograph) �P�s���E�����A s (series) �p���A j (journal) �V���E�G���A u (unpublished material) �_���┲������A a (article) �P�̋L���E���Ȃ�
- type ����
- �ޕʁB�l�̗�F abbreviated, main, subordinate �i����⏬���o�����j, parallel �i�ʑ�A�O����ɂ��ʖ����j�B
���p�⊄�蒍�̃^�O�i <q> �A <gloss> �j�ɂ��A�K�v�Ȃ� rend ������t����B
�@(1)
�@On the one hand the Nibelungenlied�@is associated with the new
�@rise of romance of twelfth-century France, the romans
�@d'antiquité, the romances of Chrétien de Troyes, and the German
�@adaptations of these works by Heinrich van Veldeke, Hartmann von Aue,
�@and Wolfram von Eschenbach.
�@(2)
�@On the one hand the <title>Nibelungenlied</title> is associated
�@with the new rise of romance of twelfth-century France, the
�@<foreign>romans d'antiquité</foreign>, the romances of
�@Chrétien de Troyes, ...
�@(3)
�@On the one hand the <hi rend=italic>Nibelungenlied</hi>
�@is associated with the new rise of romance of twelfth-century
�@France, the <hi rend=italic>romans d'antiquité</hi>,
�@the romances of Chrétien de Troyes, ...
(1)�̕��͂̋����������߂���A(2)�̂悤�ȃ^�O�t���ɂȂ�B�܂��A�O�����������q����A(3)�̂悤�ȃ^�O�t���ɂȂ邾�낤�B
���p�Ȃ�
���p���̐������A�ł���Έȉ��̂悤�ɖ������邱�Ƃ����߂�B
- <q>
- ��b�E�v�l���e�̕\���B�����ł́A����E�p��Ɏg���B
- type ����
- ��b( spoken )�E�S�b( thought �F�Ɣ���)�̋�ʁB
- who ����
- ��b��������B
- <mentioned>
- ���y��
- <soCalled>
- ������B�ӔC����̈��p�B
- <gloss>
- ���蒍�E�
- target ����
- �֘A���������B
���p�̎���B
Few dictionary makers are likely to forget Dr. Johnson's description of the lexicographer as <q>a harmless drudge.</q>
���p�̌`���i�C�����C���A�����A�u���b�N���p���j�� rend �����Ŏ����ׂ��ł���B���p���̎�ނ�\���ɂ����̑������g����B
����̕\���́A�O������p�ŋ�邱�ƂŎ������Ƃ��ł���B
<p><q>Who-e debel you?</q> — he at last said —<q>you no speak-e, damme, I kill-e.</q> And so saying, the lighted tomahawk began flourishing about me in the dark.
�����Q�̈��p���P�̉�b�Ƃ��ĂȂ����Ƃ��Ӗ������ꍇ�ɂ́A�����N������ next �� prev ���g����B�i�u�W�v���Q�ƁB�j
���p�����̓T����b�҂������ɂ́A who �������g���B
<q who=Wilson>Spaulding, he came down into the office just this day eight weeks with this very paper in his hand, and he says:—<q who=Spaulding>I wish to the Lord, Mr. Wilson, that I was a red-headed man.</q></q>
�d�q�e�L�X�g�̍쐬�҂́A���p�����c�����A�^�O�Œu�������邩�����߂Ȃ���Ȃ�Ȃ��B���p������苎��ꍇ�A rend �����ɂ���Č����̑̍ق��L�^���邱�Ƃ��ł���B
�܂��A�����̏ꍇ�Ɠ������A�����ĉ��߂���̂łȂ��A�P�� <hi rend=quoted> �ŕЂÂ���ق����悢�ꍇ������B
�O����̕\��
���ʑ��� lang ���^�O�ɕt������B�K�ȊY���v�f���Ȃ��ꍇ�A <foreign> �v�f�� lang �����������ă^�O�t������B
Have you read <title lang=deu>Die Dreigroschenoper</title>? The court issued a writ of <term lang=lat>mandamus</term>. John has real <foreign lang=fra>savoir-faire</foreign>. <mentioned lang=fra>Savoir-faire</mentioned> is French for know-how.
�V�@���L
�r���E�㒍�E���O�����̑��A�ꏊ�ɂ�����炸�A�����⒍�߂ɂ͓��� <note> �v�f���g���B
- type ����
- ���L�̌^�������B
- resp ����
- ���ߎ҂������B�l�̗�Fauthor �A editor ���A���͒��ߎ҂̃C�j�V�����ȂǁB
- place ����
- ���L�̏o���ʒu�Binline�Ainterlinear�i�s�ԁj�Aleft�i���}�[�W�����j�Aright�Afoot�Aend ���B
- target ����
- ���L������ʒu�i��̏��߂Ȃǁj�������B
- targetEnd ����
- ���L�̋y�Ԕ͈͂̍Ō�������B
- anchored ����
- �����{�����L�̎Q�ƌ��𐳊m�Ɏ����Ă��邩�ǂ������B
���L�ԍ��܂��͎��ʒl���K�v�ȏꍇ�A n �������g���B�܂��A���߂������ł��邩�A�Z���E�ҏW�̒��ł��邩�� resp �Ŗ������邩�A�ǂ̎�ނ̒��ł��邩�� TEI �w�b�_�ŏq�ׂ邱�ƁB
Collections are ensembles of distinct entities or objects of any sort. <note place=foot n=1>We explain below why we use the uncommon term <mentioned>collection</mentioned>instead of the expected <mentioned>set</mentioned>. Our usage corresponds to the <mentioned>aggregate</mentioned> of many mathematical writings and to the sense of <mentioned>class</mentioned> foundin older logical writings.</note> The elements ...
<lg id=RAM609><note place=margin>The curse is finally expiated</note> <l>And now this spell was snapt: once more</l> <l>I viewed the ocean green,</l> <l>And looked far forth, yet little saw</l> <l>Of what had else been seen ‐</l>
�W�@���ݎQ�Ƃƃ����N
�@�A�g���|�C���^ �@�B�����Ȃ��`�ł̃����N����鑮��
�@����� SGML �������ł̒P���ȑ��ݎQ��
- <ref>
- �Q�ƃ^�O�B
- <ptr> (pointer)
- �|�C���^�B
<ptr> ���|�C���^����邾���̋�v�f�ł���̂ɑ��āA <ref> �͑��ݎQ�Ƃ��̂��̂��܂ރe�L�X�g�����܂ށB�܂��A <ptr> ���V���{����A�C�R���A�{�^���Ƃ��������t�ȊO�̂��̂ɂ�郊���N����邪�A����͌��t�ɂ���ă����N����镶�����Y�V�X�e���ł����ɗ��B
�ǂ���ɂ����ʂ��āA�ȉ��̑������g����B
- target ����
- �|�C���^�̕W�I�������B
- type ����
- �|�C���^�̗ޕʂ������B
- targType ����
- �|�C���^�̎w�������v�f�̃^�C�v���B
- crDate ����
- �|�C���^�̍쐬�����B
- resp ����
- �|�C���^�̍쐬�ҁB
See especially <ref target=SEC12>section 12 on page 34</ref>. See especially <ptr target=SEC12>.
target �����̒l�́A���̕����� SGML ID �i���{������߂��j�ł���B���̗�ł́A <div1> �v�f���Q�Ƃ��Ă���B
... see especially <ptr target=SEC12>. ... <div1 id=SEC12><head>Concerning Identifiers... ...
id �����͈�ʓI�Ȃ̂ŁA�Ⴆ�p���O���t�Ȃǂɂ��{�����Ƃ��ł���B
... this is discussed in <ref target=pspec>the paragraph on links</ref> ... <p id=pspec>Links may be made to any kind of element ...
targType �����́A�w���������v�f������̂��̂ł��邱�Ƃ������B���̌^������Ȃ��ƁA�Q�Ƃ͎��s����B SGML �p�[�T�����ł͂��̓K�����̃`�F�b�N�͂ł��Ȃ��B
... this is discussed in <ref target=dspec targType='div1 div2'> the section on links</ref>
type �����ɂ���ă����N�ނ��邱�Ƃ��ł���B resp ������ crDate �����������Ďg������F
... this is discussed in <ref type=xref resp=auto crdate=950521 target=dspec targtype='div1 div2'> the section on links</ref>
/��<s>/
�P�Ƀ����N�|�C���g����邾���Ȃ�A <anchor> �v�f��u�������ł悢�B��������^�[�Q�b�g�ɂ���Ȃ�A <seg> �v�f��u���悢�B type �����������邱�ƂŖړI�ʂɕ��ނ��邱�Ƃ��ł���B
.... <anchor type=bookmark id='ABCD'> .... .... <seg type=target id='EFGH'> ... </seg> ...
�A�g���|�C���^
�O�������ւ̎Q�Ƃ�����ꍇ�ɂ́A <xptr> �A <xref> ���g���B��L�����̑��A target �����ɑ����Ĉȉ��̑������g���B
- doc ����
- �����N��̕������B�i�f�t�H���g�̓J�����g�����B�j
- from ����
- TEI �g���|�C���^�\���ɑ����ă����N�J�n�_�������B�i�f�t�H���g�� doc �����Ŏ����ꂽ�����̑S�́B�j
- to ����
- TEI �g���|�C���^�\���ɑ����ă����N�A���_�������B�i from ������������Ă͂��߂Ė��������B�j
TEI �g���|�C���^�̃^�[�Q�b�g��\��������@�̏ڍׂ́A TEI P3 �K�C�h���C�����Q�ƁB
<xptr>�i���� <xref>�j�́A doc �����ɃG���e�B�e�B����₤�����ŁA���̕����S�̂��w�����Ƃ��ł���B���̂��߂ɂ́A�G���e�B�e�B���� litemods.ent �g���t�@�C���ɁA���͎g�p���Ă��� SGML �I�[�T�����O�E�\�t�g�ɌŗL�̕��@�Ő錾���Ă����Ȃ��Ă͂Ȃ�Ȃ��B�i�u15�v���Q�ƁB�j
see <xref doc=P3>The TEI Guidelines, passim</xref>
from �����́Adoc �����Ŏ����ꂽ�����̒��̂���ʒu�������B TEI �g���|�C���^�\���ɏ]���ċL�q���邪�A�����܂�ł����A�w���ʒu�� steps �̕��тŎ�����A�e�X�� step �͒��O�� step �Ŏ������ʒu����̑��ΓI�Ȉʒu���L�q����B�Ⴆ�A��Q�͂̑�Q�i���̂R�Ԗڂ̕����w������ɂ́A���߂ɑ�Q�́A���ɑ�Q�i���A�Ō�ɑ�R�����w������Ƃ�����ł���B�������� SGML �̍l�����i parent �A descendant �A preceding ���B�����}�Q�ƁB�j�ɂ�邩�A���邢�͂����Ƒ�܂��ɁA�e�L�X�g�̌^�⎚��̈ʒu�Ȃǂł��悢�B SGML �L�@�łȂ��Ƃ��A�����̃V�X�e���ʼn摜���̈ʒu���w�����邱�ƂȂǂ��ł���B
from ������ to �����́A�����L�@���g���B�g���|�C���^�́A from �Ŏ������ꏊ�̍ŏ�����A to �Ŏ������ꏊ�̏I���܂ł̕������w������̂ł���B
�͂��߂ɁA�^�[�Q�b�g�ƂȂ镶�����̂���v�f�� ID �������B
<xptr doc=P3 from='id (SA)'>
����� P3 �G���e�B�e�B���� SA ���ʎq�ŕ\�����v�f�̑S�̂�I���B���̃L�[���[�h���g���āA���݂̊W�ɂ���đ��̗v�f��I�Ԃ��Ƃ��ł���B
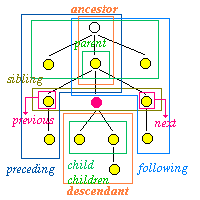
- child
- �q�v�f�i���̗v�f�kSA�l�Ɋ܂܂��v�f�j
- ancestor
- �c��v�f�i���̗v�f�ځA�ԐڂɊ܂ޗv�f�j
- previous
- �Z�v�f�i�e�v�f�������ŁA��s������́j
- next
- ��v�f�i�e�v�f�������ŁA�㑱������́j
- preceding
- �e�v�f���܂߁A���̗v�f�ɐ�s�������
- following
- �e�v�f���܂߁A���̗v�f�Ɍ㑱�������
���ꂼ��ɁA�Ⴆ�� children �i�q�v�f�̏W���j�A ancestors �i��ʗv�f�̏W���j�A siblings �i�Z��v�f�̏W���j�Ȃǂ��܂܂��B�����̂��߂Ɏ��̂��̂��J�b�R�ł����������X�g�𑱂��Ă��悢�B
- �����̐��ɂ���Ďw���͈͂����肷��B�i +1 �͌��݈ʒu����n�߂čŏ��Ɍ��������v�f�������B -1 �͍Ō�Ɍ��������v�f�������B�j���́A all �͌��������v�f���ׂĂ������B
- ���̎��ʎq�ɂ���ėv�f�̌^�������B���́A����i�A�X�^���X�N�j�ɂ���ĔC�ӂ̗v�f�������B
- �������ƒl�ɂ���ĊY���̗v�f����肷��B
���� SA ���ʎq�����v�f�Ɋ܂܂���R�i����I���������́B
<xptr doc=P3 from='id (SA) child (3 p)'>
���l�ɁA P3 �G���e�B�e�B�� TEI �K�C�h���C�����Q�Ƃ��Ă���Ƃ���A���͊g���|�C���^�\�����K�肳��Ă��铯���� 14.2.2 �߂�I�����Ă���B
For full details, see<ref doc=P3 from='id (SA) child (2 div2) child (2 div3)'> TEI Extended pointer syntax definition </ref>
���̗�ł́A from ������ to �������g�����Ƃɂ��A�����̍\���ɂ�炸�A�Y�����邷�ׂĂ̕����v�f���^�[�Q�b�g�Ƃ��Ă���B�i�������A ABC �̏I��肪 XYZ �̎n�܂����ł�������G���[�ł���B�j
<xptr doc=P1 from='id (xyz)' to='id (abc)'>
���̍\�����g�����ƂŁA���ɕ��G�ȋL�q���ȒP�ɂł���B���́A lang �����̒l�� LAT �ł���A�ł� SA �̎n�܂�ɋ߂���s�v�f <head> ��I���������̂ł���B
<xptr doc=P3 from='id (SA) preceding (1 head lang lat)'>
���� doc �����ɉ��̒l���Ȃ���A���݂̕������ΏۂƂȂ�B����(1)�A(2)�͓����Ӗ���\���B
(1) <ptr target=X1> (2) <xptr from='id (X1)'>
�B�����Ȃ��`�ł̃����N����鑮��
�ȉ��̃����N������ TEI Lite DTD �̋��ʑ����ŁA���ʂȖړI�Ɏg���B
- ana (analysis) ����
- ���߂Ƃ̃����N
- corresp (corresponding) ����
- �����v�f�i�P���E�����j�Ƃ̃����N
- next ����
- ���̂̒��Ŏ��̗v�f�Ƀ����N
- prev ����
- ���̂̒��őO�̗v�f�Ƀ����N
ana �����́A���ۓI���́E���߂��L�����������w������B�i�u16�v���Q�ƁB�j
�Ⴆ�A "John loves Nancy." �Ƃ������̕��@�I��͂��^�O�t������B���ꂼ��ASVO�ANP1�AVV1 �Ƃ��� id �������������������������̂ǂ����ɂ���킯�ł���B�Ȃ��A type �������� seg �v�f�̎g�����ɒ��ӁB
/�����@/
<seg type=sentence ana=SVO>
<seg type=lex ana=NP1>John</seg>
<seg type=lex ana=VVI>loves</seg>
<seg type=lex ana=NP1>Nancy</seg>
</seg>
corresp �����́A�e�L�X�g���̂Q�̗v�f�����ʂ��邱�Ƃ�\���B������e�L�X�g�Ō���Ɩ|�������т����B
<seg lang=FRA id=FR1 corresp=EN1>Jean aime Nancy</seg> <seg lang=ENG id=EN1 corresp=FR1>John loves Nancy</seg>
���̋@�\�́A�Ⴆ�����̑O���Ɖ��W��\���̂ɂ����p�ł���B
<p><title id=shirley>Shirley</title>, which made its Friday night debut only a month ago, was not listed on <name id=nbc>NBC</name>'s new schedule, although <seg id=network corresp=nbc>the network</seg> says <seg id=show corresp=shirley>the show</seg> still is being considered.
next ������ prev �����́A�s�A���̗v�f���݂��ɂȂ��̂Ɏg���B
<q id=Q1a next=Q1b>Who-e debel you?</q> — he at last said — <q id=Q1b prev=Q1a>you no speak-e, damme, I kill-e.</q> And so saying, the lighted tomahawk began flourishing about me in the dark.
�X�@�ҏW�̂��߂̏��u
���͂ɂ����āA�����̑̍ق�ێ����A���ҏW��̏��u�������荞�ނ��߂̕��@���q�ׂ�B
�ҏW�ҁi�Z���ҁj���������u�����v(correction) ���邽�߂̗v�f�B
- <corr>
- �����̌��Ǝv������̒����B
- sic ����
- ���Ǝv��������L���B
- resp ����
- �������s�����ҏW�E�Z���҂̋L�ځB
- cert (certainty)
- �����ɂ�錴���̐M���x�B
- <sic>
- �}�}�i��L�E��A�̕ێ��j
- corr ����
- �������̋L�ځB
- resp ����
- �������s�����ҏW�E�Z���҂̋L�ځB
- cert ����
- �����ɂ�錴���̐M���x�B
�ȉ��̗v�f�́A�u�����v(normalization) �̂��߂̗v�f�ł���B�����̈�ѐ��E�����I�������Ȃǂ�ړI�Ƃ����ύX�ł���B
- <orig> (original) �v�f
- �����̓ǂݕ�
- reg (regularized) ����
- ���������ǂݕ�
- resp ����
- �Z���҂� id
- <reg> �v�f
- ���������ǂݕ�
- orig ����
- �����̓ǂݕ�
- resp ����
- �Z���҂� id
�Ⴆ�A(1)�̕��� Gifford �ɂ���Č��ƃX�y���̌����w�E����Ă���B�i�@ table �� babbled �̌��A�A a' �� he �́A feelds �� fields �̌�L�j�ނ̐������}�[�N�t���ŕ\�����̂�(2)�ł���B
(1) ... for his nose was as sharp as a pen and a' table of green feelds
(2) ... for his nose was as sharp as a pen and <reg sic="a'">he</reg>
<corr sic='table' ed=Gifford>babbl'd</corr> of green
<reg sic='feelds'>fields</reg>
10�@�ȗ��E�폜�E�t��
�ȗ��E��������₢�A�����̍Č��ɕK�v�ȏ���₤���߂̕��@�B
- <add> �v�f
- �����ҁE���ʎҁE���ߎҁE�Z���ғ��ɂ�鎚��̏���������B
- place ����
- ����������������B�l�̗�F inline,supralinear�i�s�̏�j,infralinear�i�s�̉��j,left�i���}�[�W���j,right,top,bottom ���B
- <gap> �v�f
- �ʖ{���̏ȗ����B TEI �w�b�_�ɗ��R�̋L�q�����邩�A���͔��ǂł��Ȃ����ɂ��B
- desc (description) ����
- �ȗ����̋L�q�B
- resp
- �ȗ���ۑ������ҏW�ҁi���ʎҁE�}�[�N�t���ӔC�ҁj�� id ���B
- <del> �v�f
- �폜���ꂽ����̋L�q�B�폜���L�E�����E��₌��ȂǁB
- type ����
- �K�X�A�폜�̗ތ^���L�q����B
- status ����
- �폜�̓K�ۂȂǂ��L�q�ł���B
- hand ����
- �폜�҂� id ���B
- <unclear> �v�f
- ���Ǖs�\�̎�����L�q�B
- reason ����
- ���ʂł��Ȃ����R�B
- resp ����
- ���f�҂� id ���B
�폜���L�̎���������B(1)�̟������폜���邱�Ƃ��A(2)�Ŏ����B
(1) The following elements are provided for
for simple editorial interventions.
(2) The following elements are provided for
<del hand=LB>for</del> simple editorial interventions.
�����œ����𗎂Ƃ��Ă����ꍇ�B
(1) The following elements provided for
for simple editorial interventions.
(2) The following elements <add hand=LB>are</add> provided for
<del hand=LB>for</del> simple editorial interventions.
���l�ɁA�����҂ɂ�錴�e�̍Z���Ȃǂ��}�[�N�A�b�v�ł���B�Ⴆ�A���e�� galls ������ dogs ��}�������ꍇ�́A���̂悤�ɂȂ�B
How it <del hand=DHL type=overstrike>galls</del> <add hand=DHL place=supralinear>dogs</add> me,what a galling shadow
<unclear> �v�f�� <gap> �v�f���Ɏg���āA���Ǖs�\�����̏ȗ����������Ƃ��ł���B�i���̗�ł́A��������L�q���邽�߂� <add> �^�O���g���Ă���B�j
One hundred & twenty good regulars joined to me <unclear><gap reason='indecipherable'></unclear> & instantly, would aid me signally <add hand=ed>in?</add> an enterprise against Wilmington.
<del> �v�f�́A�폜�̎|���L���Ȃ���폜�������e�L�X�g�̈ꕔ���Ƃ��ċL�q���邪�A <gap> �v�f�͔��ǂ̉ۂɂ������Ȃ��e�L�X�g�̏ȗ������L�����̂ł���B�R�[�p�X�Ȃǂł́A�O����̒������p���͏ȗ����邩������Ȃ��B
<p> ... An example of a list appearing in a fief ledger of
<name type=place>Koldinghus</name> <date>1611/12</date>
is given below. It shows cash income from a sale of
honey.</p>
<q><gap desc='quotation from ledger'
reason='in Danish'></q>
<p>A description of the overall structure of the account is
once again ... </p>
���̃R�[�p�X�ł́i���ɃX�L���i�������̂悤�ɕ��y����ȑO�̂��́j�A�}�␔���͏ȗ�����Ă���B
<p>At the bottom of your screen below the mode line is the <term>minibuffer</term>. This is the area where Emacs echoes the commands you enter and where you specify filenames for Emacs to find, values for search and replace,and so on. <gap desc='diagram of Emacs screen' reason='graphic'> </p>
11�@���O�E���t�E���l�E����
���O�Ə̌� (referring string)
�̌ĂƂ͐l��ꏊ�A���Ȃǂ��Q�Ƃ����ł���B
- <rs> (referring string) �v�f
- ���ʖ�����̌�
- type ����
- �Q�Ƃ��镨�̎�ށB�l�̗�F person,place,ship,element ���B
- <name> ����
- �ŗL�����i������j
- type ����
- �Q�Ƃ��镨�̌^�B
<q>My dear <rs type=person>Mr. Bennet</rs>, </q> said his lady to him one day, <q>have you heard that <rs type=place>Netherfield Park</rs> is let at last?</q> It being one of the principles of the <rs type=organization>Circumlocution Office</rs> never, on any account whatsoever, to give a straightforward answer, <rs type=person>Mr Barnacle</rs> said, <q>Possibly.</q>
���̗�ł́A <rs> �v�f���ŗL�����i������j�̌`�����Ă��Ȃ��ꍇ���܂߂āA���ׂĂ̐l��ꏊ���ւ̎Q�Ƌ�Ƀ^�O�t������Ă���B
�i�� <rs> �� <name> ���܂��Ă���B�ȉ����Q�ƁB�j
<q>My dear <rs type=person>Mr. Bennet</rs>,</q> said <rs type=person>his lady</rs> to him one day...
����ƑΏƓI�ɁA <name> �v�f�͌ŗL�����������琬��B <rs> �v�f�Ɠ����悤�ȈӖ��Ɏg�����Ƃ��ł��A�܂����ʖ����ƌŗL�����̍������� referring string �ł� <rs> �v�f�̒��Ƀl�X�g�����Ďg�����Ƃ��ł���B
���O��P�� name �Ń^�O�t�������̂ł́A�Q�Ƃ̂��߂ɂ͏\���ł͂Ȃ��B���͂̒��ɂ́A����������Ƃ����`�Ŗ��O���o�Ă���킯�ł͂Ȃ��B��L�̗v�f��ގ��̗v�f�ɁA�ȉ��̑�����t���邱�Ƃ��ł���B
- key �v�f
- ���̖��O�ɑ��� id ���i�f�[�^�x�[�X�̃L�[���ڂ̂悤�Ȃ��́j
- reg (regularized) �v�f
- ���K�����ꂽ�\�L
key �����́A�����ɎU�݂���l����n���ւ̂��ׂĂ̎Q�Ƃ��W�߂��i�Ƃ��ėL�v�ł���B
<q>My dear <rs type=person key=BENM1>Mr. Bennet</rs>, </q> said <rs type=person key=BENM2>his lady</rs> to him one day, <q>have you heard that <rs type=place key=NETP1>Netherfield Park</rs> is let at last?</q>
�O�q�� reg (regularization) ���������̂悤�ɏ̌Ă̕W�������ꂽ�`���L�q���邽�߂Ɏg����̂Ƌ�ʂ��邱�ƁB
<name type=person key=WADLM1 reg='de la Mare, Walter'>
Walter de la Mare
</name> was born at
<name key=Ch1 type=place>Charlton</name>, in
<name key=KT1 type=county>Kent</name>, in 1873.
���t�Ǝ���
- <date> �v�f
- ���t
- calendar ����
- ���t���L�ڂ���V�X�e�����̓J�����_�[
- value ����
- ����̌`���ł̓��t�i yyyy-mm-dd ���j
- <time> �v�f
- ����
- value ����
- ����̌`���ł̎���
value �����́A ISO 8601 ���̌`���ɏ]���B�ȗ��`��͈͂Ŏ������Ƃ��ł���B�B���ȕ\���ł��A�͈͂̋�肪������A exact �����ŕ\�����Ƃ��ł���B
<date value='1980-02-21'>21 Feb 1980</date> <date value='1990'>1990</date> <date value='1990-09'>September 1990</date> Given on the <date value='1977-06-12'>Twelfth Day of June in the Year of Our Lord One Thousand Nine Hundred and Seventy-seven of the Republic the Two Hundredth and first and of the University the Eighty-Sixth.</date> <l>specially when it's nine below zero <l>and <time value='15:00'>three o'clock in the afternoon</time>
����
�����ł�������邪�A���̕����Ƃ̋�ʂ͔�r�I���Ăł���B��ʂ̂��߂ɂ́A <num> �v�f���g���B
- <num> �v�f
- �����E�ԍ�
- type ����
- ���l�̌`���B�l�̗�F cardinal�i��j,ordinal�i�����j,fraction�i�����j, percentage���B
- value ����
- ���l�i�A�v���P�[�V�����Ɉˑ����Ȃ��`���ŋL���B�j
<num value='33'>xxxiii</num> <num type=cardinal value='21'>twenty-one</num> <num type=percentage value='10'>ten percent</num> <num type=percentage value='10'>10%</num> <num type=ordinal value='5'>5th</num>
����Ƃ��̓W�J
��������̂܂g���ꍇ���W�J����ꍇ�����邾�낤�B�}�[�N�t������ɂ́A�ȉ��̗v�f���g���B
- <abbr> (abbreviation) �v�f
- ����
- expan (expansion) ����
- ����̐������̂��L���B
- type ����
- ����̕��ށB�l�̗�F contraction�i�k��j,suspension�i�ȗ��j,brevigraph�i���L�j,superscription�i�����j,acronym �i�������j���B���邢�́Atitle�i�h�́E�����j,geographic,organization ���B��̐������悭�\�����ނ��H�v����B
<abbr> �v�f�́A��������B��Ȃǂ���ʂ���̂ɖ��ɗ��B
We can sum up the above discussion as follows: the identity of a <abbr>CC</abbr> is defined by that calibration of values which motivates the elements of its <abbr>GSP</abbr>; Every manufacturer of <abbr>3GL</abbr> or <abbr>4GL</abbr> languages is currently nailing on <abbr>OOP</abbr> extensions.
�@�\�ɂ���� type �������g������B
<name><abbr type=title expan='Doctor'>Dr.</abbr> <abbr type=initial expan='Marilyn'>M.</abbr> Deegan</name> is the Director of the <abbr expan='Computers in Teaching Initiative' type=acronym> CTI</abbr> Centre for Textual Studies.
�Z��
<address> �v�f�́A�Z���������B����ɁA�Z���̊e�s�� <addrLine> �v�f�Ŏ����B
<address> <addrLine>Computer Center (M/C 135)</addrLine> <addrLine>1940 W. Taylor, Room 124</addrLine> <addrLine>Chicago, IL 60612-7352</addrLine> <addrLine>U.S.A.</addrLine> </address>
�Z���̌ʗv�f�́A�O�q�� <name> �v�f���g���B
<address> <addrLine>Computer Center (M/C 135)</addrLine> <addrLine>1940 W. Taylor, Room 124</addrLine> <addrLine><name type=city>Chicago</name>, IL 60612-7352</addrLine> <addrLine><name type>=country>USA</name></addrLine> </address>
12�@���X�g
���X�g�ɂ́A�ԍ������X�g�E�ԍ��������X�g�E�p�ꃊ�X�g�Ȃǂ�����B�ǂ�����ڂ̕��тł���A���ڂ̂͂��߂ɂ̓��x���i�p�ꃊ�X�g�ł͗p�ꂻ�̂��́j������B
- <list> �v�f
- �e�L�X�g���ڂ̕���
- type ����
- ���X�g�̌`���B�l�̗�F orderd�i�ԍ������X�g�j,bulleted �i�����␔���k�����ɊW�Ȃ��H�l�E�ۈ�̂������X�g�j,gloss�i���p��W�B <label> �v�f�� <item> �v�f�Ƃ��琬��B�j,simple �i����̃��X�g�j���B
- item �v�f
- ���X�g�̍\���v�f�B
- label �v�f
- ���x���B���ڂ������B�p��W�ł́A���o���̏p�ꂪ�����ɂ���B
�ŏ��� <item> �̑O�ɂ́A���X�g�̃w�b�_�ƂȂ� <head> ��u���Ă��悢�B���X�g�̔ԍ����͕s�v�ł���A����ꍇ�ɂ� n �������e���ڂɂ��邩�A�i�܂�Ɂj<label> �v�f���g���B
���̗�́A�ǂ�������Ӗ���\���Ă���B
(1) <list> <head>A short list</head> <item>First item in list.</item> <item>Second item in list.</item> <item>Third item in list.</item> </list> (2) <list> <head>A short list</head> <item n=1>First item in list.</item> <item n=2>Second item in list.</item> <item n=3>Third item in list.</item> </list> (3) <list> <head>A short list</head> <label>1</label><item>First item in list.</item> <label>2</label><item>Second item in list.</item> <label>3</label><item>Third item in list.</item> </list>
�������X�g�ɈقȂ����X�^�C����������̂͂悭�Ȃ��B
�p��W�� term �����x���Ƃ��ă^�O�t�����A gloss ������(item)�Ƃ��ă^�O�t������B���� term , gloss �ƁA���ʂ̃e�L�X�g�̂ǂ��ɂł��u���� <term> �v�f�A <gloss> �v�f�Ƃ͓������̂ł���B
<list type=gloss> <head>Vocabulary</head> <label lang=enm>nu</label> <item>now</item> <label lang=enm>lhude</label> <item>loudly</item> <label lang=enm>bloweth</label> <item>blooms</item> <label lang=enm>med</label> <item>meadow</item> <label lang=enm>wude</label> <item>wood</item> <label lang=enm>awe</label> <item>ewe</item> <label lang=enm>lhouth</label> <item>lows</item> <label lang=enm>sterteth</label> <item>bounds, frisks</item> <label lang=enm>verteth</label> <item lang=lat>pedit</item> <label lang=enm>murie</label> <item>merrily</item> <label lang=enm>swik</label> <item>cease</item> <label lang=enm>naver</label> <item>never</item> </list>
���X�g�������ƕ��G�ȏꍇ�A�ނ��� table �ƍl���āA��p�� TEI �^�O�E�Z�b�g���g���ق����悢�B
���X�g�͂�����ł�����q�ɂł���B
<list type=gloss>
<label>EVIL</label>
<item>
<list type=simple>
<item>I am cast upon a horrible desolate island, void
of all hope of recovery.</item>
<item>I am singled out and separated as it were from
all the world to be miserable.</item>
<item>I am divided from mankind — a solitaire; one
banished from human society.</item>
</list> <!-- end of first nested list -->
</item>
<label>GOOD</label>
<item>
<list type=simple>
<item>But I am alive; and not drowned, as all my
ship's company were.</item>
<item>But I am singled out, too, from all the ship's
crew, to be spared from death...</item>
<item>But I am not starved, and perishing on a barren place,
affording no sustenances....</item>
</list><!-- end of second nested list -->
</item>
</list><!-- end of glossary list -->
���X�g�́A�K���������s���Ȃ��Ƃ��悢�B
On those remote pages it is written that animals are divided into <list rend="run-on"><item n='a'>those that belong to the Emperor,<item n='b'> embalmed ones, <item n='c'> those that are trained, <item n='d'> suckling pigs, <item n='e'> mermaids, <item n='f'> fabulous ones, <item n='g'> stray dogs, <item n='h'> those that are included in this classification, <item n='i'> those that tremble as if they were mad, <item n='j'> innumerable ones, <item n='k'> those drawn with a very fine camel's-hair brush, <item n='l'> others, <item n='m'> those that have just broken a flower vase, <item n='n'> those that resemble flies from a distance.</list>
�����I�ȍ��ڂ̃��X�g�ɂ��ẮA <listBibl> �v�f���g���B�i���߂��Q�ƁB�j
13�@�����I���p
�����ړI�̏����I�Ȉ��p�́A�e�L�X�g�̈���ɍۂ��Ă�����ƕ�����悤�ɋ敪������邾�낤�B <bibl> �v�f�́A�����I���p������{���Ƌ�ʂ���B
���̑��A���̃^�O��K�X���p����Ƃ悢�B
- <author> �v�f
- �����I���p�̒��̌�����ҁi�@�ցj��
- <biblScope> �v�f
- �����I���p�͈̔́i�y�[�W���ⓖ�Y�������j
- <date> �v�f
- ���t
- <editor> �v�f
- �Q���I����i�ҏW�j�ҁi�@�ցj��
- role ����
- ���i�E�����i�f�t�H���g�� editor �A���� translator,compiler,illustrator ���B�j
- <imprint> �v�f
- ����E�o�Ŏ�
- <publisher> �v�f
- �i��\�́j�o�ŋ@�֖��E���s��
- <pubPlace> �v�f
- �o�Œn
- <series> �v�f
- �p���E�V���[�Y��
- <title> �v�f
- �W��i��i���E�L�����E�����E�����E�p�������j
- type ����
- ���ށi main,subordinate�i����Ȃǁj ���j
- level ����
- �W��̏����I�ȊK�w�i�u�U�v���Q�ƁB�j
�ҏW���L�̃^�O�t���̈��B(1)�̃J�b�R�������L�̌����ł���B
(1) He was a member of Parliament for Warwickshire in 1445,
and died March 14, 1470 (according to Kittredge, Harvard
Studies 5. 88ff).
(2) He was a member of Parliament for Warwickshire in 1445,
and died March 14, 1470 (according to
<bibl><author>Kittredge</author>, <title>Harvard
Studies</title> <biblScope>5. 88ff</biblScope></bibl>).
�����I���p�̃��X�g�ɂ� <listBibl> �v�f���g���B����� <bibl> �v�f�̕��тł���B����́A�u22 ���t�@�����X�v���̃��X�g���Q�ƁB�j
14�@�e�[�u���i�\�j
�e�L�X�g�����V�X�e���ɂƂ��ăe�[�u���i�\�j�͑傫�ȉۑ肾���A�ȒP�ȕ\�͕��͒��ɂ悭����邽�߁A�ȒP�Ȃ��̂ł����Ă���p�̃^�O���K�v�ł���B
- <table> �v�f
- �s�Ɨ�Ƃ��琬��\�`���̃e�L�X�g
- rows ����
- �s���������B
- cols (columns) ����
- �������B
- <row> �v�f
- �\�̂P�s
- role ����
- �s���̊e�Z���̏��B�l�̗�F label �i���x���E���ʃf�[�^�j,data �i�����f�[�^�j���B
- <cell> �v�f
- �\�̃Z��
- role ����
- �Z���̏��B�l�̗�F label �i���x���E���ʃf�[�^�j,data �i�����f�[�^�j���B
- cols ����
- �Z���̐�߂��
- rows ����
- �Z���̐�߂�s��
���́A�_�j�G���E�f�t�H�[�������a�N�Ŏg�������҂̈ꗗ�\�̗�ł���B
<p>It was indeed coming on amain, for the burials that
same week were in the next adjoining parishes thus:—
<table rows=5 cols=4>
<row role='data'>
<cell role='label'>St. Leonard's, Shoreditch</cell>
<cell>64</cell> <cell>84</cell> <cell>119</cell></row>
<cell role='label'>St. Botolph's, Bishopsgate</row>
<cell>65</cell> <cell>105</cell> <cell>116</cell></row>
<cell role='label'>St. Giles's, Cripplegate</row>
<cell>213</cell> <cell>421</cell> <cell>554</cell></row>
</table>
<p>This shutting up of houses was at first counted a very cruel
and unchristian method, and the poor people so confined made
bitter lamentations. ... </p>
15�@�}�ƊG
�ǂ�Ȃɏ���C�̖������͂ł��A�}����}���G���炢�͊���������̂��B�����ɂ���Ă͕��͂Ɖ摜�Ƃ��s���Ȃ��̂�����A���̃��f�B�A����g����d�q�I�����ł�����炪����ɉz�������Ƃ͂Ȃ��B
�}�[�N�A�b�v�́A�ȉ��̃^�O�ɂ���ăe�L�X�g���ł̃O���t�B�b�N�̂���ꏊ���L�������ł悭�A���邢�͓��e��Z���������Ă��悢�B���l�����ꂽ�O���t�B�b�N��d�q���e�L�X�g�ɖ��ߍ��ޏꍇ�����l�ł���B
- <figure> �v�f
- �O���t�B�b�N�̑}�������n�_�������B
- entity ����
- ���l�����ꂽ�O���t�B�b�N���܂ގ��̖̂��O
�i TEI �w�b�_�Œ�`�ς݁j
- <figDesc> �v�f
- �O���t�B�b�N�̌����ڂ���e�͂ŋL�q��������
�i�}��\�����Ȃ��ꍇ�ɗp����B�j
�O���t�B�b�N�ɕt�����錾����́A�w�b�_��L���v�V�����̂悤�ɁA <figure> �v�f�̒��� <head> �� <p> �i�K�v�Ȑ��Ԃ�j�̌`�Ŋ܂߂Ă悢�B
�摜�̐����́A���� <figDesc> �v�f�Ȃǂŕ₤�̂��悢�B����ɂ���āA�A�v���P�[�V�������O���t�B�b�N��\���ł��Ȃ��ꍇ��A���o�s���R�҂�������c���ł���悤�ɂ���ꍇ�ȂǂɎg���B�i�����������͂́A�������̖{���Ƃ͌��Ȃ��Ȃ��̂����ʂł���B�j
�O���t�B�b�N�̈ʒu�������}�[�N������B�i�v�f���e�����������ꍇ�ł��A�I���^�O�͏ȗ��ł��Ȃ��B�j
<pb n=412> <figure></figure> <pb n=413>
�O���t�B�b�N�̃^�C�g���́A <head> �v�f�Ŏ������Ƃ������B���̍ہA�Z�����������ꂽ�����֗����낤�B
<figure>
<head>Mr Fezziwig's Ball</head>
<figdesc>A Cruikshank engraving showing Mr Fezziwig leading
a group of revellers.</figdesc>
</figure>
���l�����ꂽ�O���t�B�b�N�f�[�^�𗘗p�ł���ꍇ�A�������̓K�Ȉʒu�ɖ��ߍ��߂�Ȃ��悢�B�G�Ȃǂ͑��̃G���e�B�e�B�i�t�@�C�����j�ɕ�����A�L�@�i�t�H�[�}�b�g�A�t�@�C���`���j���قȂ��Ă���̂����ʂł���B TEI Lite DTD �ł́A CGM , TIFF , JPEG �`�����A���ꂼ�� cgm , tiff , jpeg �Ƃ����i SGML �́j�L�@���ŗp���邱�Ƃ��ł��邪�A���̋L�@�ł����Ă� NOTATION �錾�����܂� DTD �ɉ�����Ȃ�p���邱�Ƃ͉\�ł���B�i SGML �� NOTATION �錾�̏ڍׂ́A TEI P3 �́u tables , formulae , and graphics �v�̏́A���͑��� SGML �֘A�����Q�ƁB�j
�摜���ǂ�ȃt�H�[�}�b�g�ł����Ă��A���͂ɖ��ߍ��ޕ��@�͕ς��Ȃ��B���߂ɁA����̌^�� SGML �G���e�B�e�B�i���́j�|�t�@�C�����̂悤�ȊO�����ʎq�|�Ǝg���Ă���L�@�Ƃ�錾����̂ł���B
<!ENTITY fezziPic SYSTEM "fezzi.tff" NDATA tiff>
���������錾�́A SGML �������̂��̂���ɓǂ܂��B TEI Lite DTD �ł́A�����̐錾�� litedecls.ent �t�@�C���A���͌��J���ʎq -//TEI U5-1995//DTD TEI Lite 1.0 Extensions//EN �������t�@�C���ɒu�����ƂɂȂ�B
���̐錾�������Ă���Ƃ��A���l�f�[�^�Ƃ��Ẳ摜�����̓K�ȏꏊ�ɖ��ߍ��ނ��߂ɂ́A <figure> �v�f�� entity �����ɒl�����邾���ł悢�B
<figure entity=fezziPic>
<head>Mr Fezziwig's Ball</head>
<figdesc>A Cruikshank engraving showing Mr Fezziwig leading
a group of revellers.</figdesc>
</figure>
16�@���߁E����
�}�[�N�A�b�v�͉��߂ƕ��͂̌`���ł���Ƃ͂悭�����邪�A�u��ϓI�v���Ɓu�q�ϓI�v���Ƃ����ł�������Ƌ�ʂ���͍̂���Ƃ������قƂ�Ǖs�\�ł���̂ɁA�u��ϓI�v�Ȕ��f���u�q�ϓI�v�Ȕ��f�����_�c���Ăт����ł��邱�Ƃɂ͕ς�肪�Ȃ��B�����ŁA���̃}�[�N�A�b�v�����ًc���₷���_�ɓǎ҂̒��ӂ𑣂����Ƃ��ł���ꍇ�ɂ̂݁A���̎�̉��߂������ċL���Ƃ����ꍇ�������̂ł���B�����ł́A���������}�[�N�A�b�v�̂��߂̗v�f���������q�ׂ�B
�����@�ɂ�镶
���߂Ƃ������̂́A���̍\���P�ʂɂ͂������Ȃ��A�{���S�̂ɂ킽����̂��B���������āA�����ȉ��߂��s���ɂ́A�{�����X�ɕ����Ɨ������P�ʁi���j�ɕ�����̂��L���ŁA���ꂪ�u�K�͓I�ȎQ�Ɓv�̗ނ̃��x���ƂȂ�킯�ł���B�X�̒P�ʂ́A�݂��Ɍ������������q�ɂ����肵�Ă͂Ȃ�Ȃ��B���̗v�f�ŒP�ʂ�\���ƕ֗��ł���B
- <s> (sentence unit) �v�f
- �{���S�̂ɋy�ԋK�͓I�ȎQ�Ƃ��s�����߂ɁA���������u���v�̒P�ʁB
- type ����
- �P�ʂ̕��ށi��F �f��A�^�ⓙ�j
���O�������Ƃ���A <s> �v�f�́A��ǖ@�Ȃǂ������@�ɂ�镶��\���̂Ɏg����B�͂��߂Ɉ������u�W�F�[���E�G�A�v�̗�B
<pb n='474'> <div1 type=chapter n='38'> <p><s n=001>Reader, I married him.</s> <s n=002>A quiet wedding we had:</s> <s n=003>he and I, the parson and clerk, were alone present.</s> <s n=004>When we got back from church, I went into the kitchen of the manor-house, where Mary was cooking the dinner, and John cleaning the knives, and I said ‐</s> <p><q><s n=005>Mary, I have been married to Mr Rochester this morning.</s></q> ...
<s> �v�f�͓���q�ɂ͂Ȃ�Ȃ��̂�����A <s> �v�f�̊J�n�͒��O�� <s> �v�f�̏I�����Ӗ����邱�ƂɂȂ�A�I���^�O���s���Ȃ킯�ł͂Ȃ��B�܂��A���̗�̂悤�ɋ敪����ꍇ�́A�{���S�̂�[����[�܂Ń^�O�t������̂��]�܂����B��������A���͂��镶���̒P�ꂷ�ׂĂ���� <s> �v�f�Ɋ܂܂�A�B��̎Q�ƊW���������Ƃ��ł���B���ʎq���������ŗB��̂��̂Ȃ�A���̗�� n �������� id �����̂ق����悢��������Ȃ��B
�ėp�̉��ߗv�f
<s> �v�f�����ėp�̕��ߗv�f�Ƃ��ẮA <seg> �v�f������܂ł����ݎQ�Ƃ�n�C�p�[�e�L�X�g�̃����N�i�u�W�v���Q�ƁB�j�̃^�[�Q�b�g����肷��̂Ɏg���Ă���B����́A�����Ԃ�僌�x���̂܂Ƃ܂���w���A�B��̎��ʎq�ł������łȂ��A���[�U�[��`�� type ���������蓖�Ă邱�Ƃ��ł����B���������āA����� TEI �K�C�h���C���ɂ͉��̒�߂��Ȃ��e�L�X�g�̓����̃^�O�t���ɗp���邱�Ƃ��ł���B
�Ⴆ�A�K�C�h���C���ɂ́A����̌��肪�ǎҁi���ҁj�Ɍ������Ē��ڂɌ�肩���镔�����}�[�N�t�����邽�߂� <apostrophe> �i�ڌĖ@�j�̗v�f�Ȃǂ͖����B���̂��߂̂P�̉�����Ƃ��ẮA����� <q> �v�f�̈��Ƃ��āi�������A who �����̒l��K�ɒ�߂邱�Ƃɂ���ċ�ʂ��邱�ƂŁj�l���邱�Ƃł��낤���B����ǂ��A�����ƊȒP�ŗp�r�̍L�������@�́A <seg> �v�f�����̂悤�ɗ��p���邱�Ƃł��낤�B
<div1 type=chapter n='38'> <p><seg type='apostrophe'>Reader, I married him.</seg> A quiet wedding we had: ...
<seg> �v�f�� type �����́A���悻�ǂ�Ȓl���Ƃ肤�邩��A�僌�x���̌��ۂȂ牽�ł��L�^���邱�Ƃ��ł���B <seg> �v�f�̒l�Ƃ��̈Ӗ�����Ƃ���� TEI �w�b�_�ɏ����Ă����̂��悢�B
<seg> �v�f�́A�������̂悭���� <s> �v�f�Ƃ͈قȂ�A���햔�َ͈�� <seg> �v�f�̓���q�Ƃ���i�l�X�g����j���Ƃ��ł���B���̂��߁A���ɕ��G�ȍ\����\�����邱�Ƃ��\���i�u�W �����N�����v���������̗����Q�ƁB�j
�������A SGML �ł͗v�f�̕�܊W�𐳂����������Ƃ����߂��A�����������Ă��Ȃ����߂ɁA�����̊K�w�\����S���ڂ݂Ȃ�����Ȕ͈͂ɑ��ĉ��߂����т������Ƃ����v���������邱�Ƃ��ł��Ȃ��B�܂��A���߂��ꎩ�̂� type �����̂Ƃ�P�̒l�ŕ\���K�v������B
����ɑ��āA <interp> �v�f�ɂ́A�ǂ���̐�������Ă͂܂�Ȃ��B���̗v�f�́A��肠���X�g���[�g�ȕ��@�ŁA���ɕ��G�ȉ��߂��}�[�N�A�b�v�ł��闊�����������������Ă���B
- <interp> (interpretation) �v�f
- �{�����́i���̒������������j���Ƀ����N����钍�߁E���߂�����B
- value ����
- ���߂̑ΏۂƂȂ鎖�ۂ������B
- resp ����
- ���߂̐ӔC��
- type ����
- ���߂̑ΏۂƂȂ鎖�ۂ̕��ށB�l�̗�F image,character,theme,allusion �i���g�j���B���́A��̓I����̋����Ă������̘_��̖��̓��B
- inst (instance) ����
- ���̗v�f���\�����́E���߂̋�̓I������w���B�i�K�p�j
- <interpGrp> �v�f
- <interp> �^�O���W�߂����́B
�����̗v�f�̂������ŁA���߂̕��ނƂ���Ɋւ����̓I����Ƃ��}�[�N�t���ł���B <seg> �v�f�ł͂�����̂��ڌĂł��邱�Ƃ���������Ȃ��̂ɑ��āA <interp> �v�f���g���A���ꂪ����ʂ̏C���I�����ɏƂ炵�Ă��̋�̓I����Ƃ��Ă̓ڌĖ@�ł���Ƃ������Ƃ��`������悤�ɂȂ�B
���̏�A <interp> �͋�v�f�ł���A�u�W �����N�����v�Ŏ�肠����ana �����ɂ�邩�A���̗v�f���g�� <inst> �����ɂ���Ď��������߂Ƀ����N���Ȃ���Ȃ�Ȃ��B����͂܂�A SGML �����̊K�w�\�����ڗ������ɂǂ̂悤�ȕ��͂��\�����Ƃ��ł��A�܂�����̃^�C�v�̕��͂��O���[�v�����邱�Ƃ��e�ՂɂȂ�킯���B�O���[�v���̂��߂ɂ́A��p�� <interpGrp> �v�f������B
��̓I�ɁA���������E��ށE�C���I�����E����̌X�̏�ʂ̈ʒu�ȂǂƂ��������͂̕��G�Ȉʑ����}�[�N�t���������Ƃ���B�Ⴆ�A�w�W�F�[���E�G�A�x�̗��ꂽ��߂ɂ��āA���邢�͓ڌ� (apostrophe) �E�֒� (hyperbole) �E�B�g (metaphor) ���̏C���I�����Ƃ��āA���邢�͋���E���g�E�����E�X�ցE�n�l���[�����X�̑�ނւ̎Q�ƂƂ��āA�����ċ���̏�ʁE�䏊�̏�ʁE����(?)���ǂ����̏�ʓ��Ƃ��āA���낢��̈Ӗ��Â���^���邱�ƂɂȂ邩������Ȃ��B�����������߂́A <text> �v�f�̂ǂ��ɂł��������B�������A�����͓����ꏊ�ɓ����̂��悢�B�i�Ⴆ�A�O�����t�����B�j���̗�F
<back>
<div1 type='Interpretations'>
<interp id='fig-apos' resp='LB, MSM'
type='figure of speech' value='apostrophe'>
<interp id='fig-hyp' resp='LB, MSM'
type='figure of speech' value='hyperbole'>
<!-- ... -->
<interp id='set-church' resp='LB, MSM'
type='setting' value='church'>
<!-- ... -->
<interp id='ref-church' resp='LB, MSM'
type='reference' value='church'>
<interp id='ref-serv' resp='LB, MSM'
type='reference' value='servants'>
<!-- ... -->
</p></div>
���̃R�[�f�B���O�̖��炩�ȏ疟�����y������ɂ́A���ʂ��������l������ <interp> �v�f��S���A <interpGrp> �v�f�ɂ���Ă܂Ƃ߂�悢�B
<back>
<div1 type='Interpretations'>
<interpGrp type='figure of speech' resp='LB, MSM'>
<interp id='fig-apos' value='apostrophe'>
<interp id='fig-hyp' value='hyperbole'>
<interp id='fig-meta' value='metaphor'>
<!-- ... -->
</interpGrp>
<interpGrp type='scene-setting' resp='LB, MSM'>
<interp id='set-church' value='church'>
<interp id='set-kitch' value='kitchen'>
<interp id='set-unspec' value='unspecified'>
<!-- ... -->
</interpGrp>
<interpGrp type='reference' resp='LB, MSM'>
<interp id='ref-church' value='church'>
<interp id='ref-serv' value='servants'>
<interp id='ref-cook' value='cooking'>
<!-- ... -->
</interpGrp>
</p></div>
�����̉��ߗv�f����܂�����A�����{���̊Y�������Ƀ����N������ɂ́A�Q�̕��@������i�ǂ��炩��������ł��A�����ł��悢�j�B
�@ ana �����́A�ǂ���̗v�f�ɂ����ʂ��Ďg�����Ƃ��ł���B�i���̗�ł́A��i���ɂQ�̏�ʐݒ肪����̂ŁA���ʎq���Q���邱�Ƃɒ��ӁB�j
<div1 type=chapter n='38'> <p id='P38.1' ana='set-church set-kitch'> <s id=P38.1.1 ana='fig-apos'>Reader, I married him.</s>...
�A <interp> �v�f�� inst ������^���邱�Ƃɂ���āA�{���̂ǂ�ȕ��������w�����邱�Ƃ��ł���B
<interp id='fig-apos' type='figure of speech' resp='LB, MSM'
value='apostrophe' inst='P38.1.1'>
<!-- ... -->
<interp id='set-church' type='scene-setting' value='church'
inst='P38.1' resp='LB, MSM'>
<interp id='set-kitchen' type='scene-setting' value='kitchen'
inst='P38.1' resp='LB, MSM'>
<!-- ... -->
<interp> �́A����̕���Ɍ���Ȃ��B�ȏ�̂悤�ȕ��w�I�ȕ���͂P�̉\���ɂ����Ȃ��B���l�ɁA���@�I�ȕi���������̂ɂ��\���g����B�u�W �����N�����v�ŋ������ᕶ�́A���̂悤�ɕ��͂��邱�Ƃ��ł���B
<interp id=NP1 type=pos value='noun phrase, singular'> <interp id=VV1 type=pos value='inflected verb, present-tense singular'> ...
17�@�Z�p����
�{���̒��S�́A�u�d�q���ȑO�v�̊����������}�[�N�t������ TEI �̕������q�ׂ邱�Ƃɂ��邪�A�V�K�̕����ɂ��Ă��������������Ă͂܂�B SGML �ł́A�����\���m�ɕ\�����Ƃ�A�������������܂��܂ȖړI�ɉ����čė��p�ł���悤�ɂ��邱�Ɓi�I�����C���̃n�C�p�[�E�e�L�X�g��u���E�Y�\�ȕ��������ł̑̍قɂ܂Ƃ܂����������A���ʂ� SGML �������琶���ł��邱�Ɓj�Ȃǂ��������Ă���B
���̂��Ƃ�e�Ղɂ��邽�߂ɁA TEI DTD �̊g���Ƃ��ċZ�p�����S�ʂƓ��� SGML �֘A�̕����̓������}�[�N�t�������p�̗v�f�� TEI Lite �͂����炩�܂�ł���B
�Z�p�����p�̒lj��v�f
���̗v�f�́A�Z�p�����̓������}�[�N�t������̂Ɏg���B
- <eg> �v�f
- ���݂Ƃ肠���Ă�����̊ȒP�ȋ�̗�B��F SGML �}�[�N�t���̎d�����ȂǁB
- <code> �v�f
- �v���O���~���O����Ȃnj`���I����̒Z���R�[�h�B
- <ident> (identifier) �v�f
- �����̎��ʎq�B��F�ϐ����A SGML �v�f���E�������ȂǁB
- <gi> (generic identifier) �v�f
- ���ʂȌ^�̎��ʎq�B��F SGML ���̎��ʎq�E�v�f���ȂǁB
- <kw> �v�f
- �`���I����̃L�[���[�h�B
- <formula> �v�f
- �� SGML �L�@�ȂǂŔC�ӂɒ���鐔�w�I�E���w�I�����B
- notation ����
- ���ɗp���Ă���L�@���B�f�t�H���g�l�� tex �i���� TeX �̑g�ŕ�����p���Ă���ӁB�j
Fortran ����̓��发�̈�߂��}�[�N�t������̂ɂ����̗v�f���g������B
<p>It is traditional to introduce a language with a program like the
following:
<eg>
CHAR*12 GRTG
GRTG = 'HELLO WORLD'
PRINT *, GRTG
END
</eg></p>
<p>This simple example first declares a variable <ident>GRTG</ident>, in
the line <code>CHAR*12 GRTG</code>, which identifies <ident>GRTG</ident>
as consisting of 12 bytes of type <kw>CHAR</kw>. To this variable,
the value <mentioned>HELLO WORLD</mentioned>
is then assigned. This is followed by a <kw>PRINT</kw> statement and an
<kw>END</kw> statement.
���̂悤�Ƀ^�O�t�����邱�Ƃɂ��A�e�L�X�g���t�H�[�}�b�g����A�v���P�[�V�����́A�K�ɓ����B�i���s��ێ�����A�t�H���g����ʂ���A���B�j���l�ɁA <ident> �� <kw> �Ȃǂ̃^�O���g���A�֗��ȍ��������̂������Ԃ�y�ɂȂ�B
<formula> �v�f�́A�{���Ƃ͋�ʂ��ꂽ�����≻�w������荞�ނ��߂Ɏg���ׂ����B�����͒ʏ�̖{���ɂ͕\��Ȃ����ʂȎ��̂��g���̂����ʂȂ̂ŁA����ȋL�@�ŕ\������K�v������B�g�p����L�@�� notation �����Ŏ����B
�i Tex �͋K��l�ɂȂ��Ă��邪�A���̋L�@���g���ꍇ�͂��炩���� DTD �̒��� notation �錾�����Ă������ƁB�j
<formula notation=tex>
\(E = mc^{2}\)
</formula>
SGML �Ή��v���Z�b�T�̏ꍇ�A <formula> �v�f�̒��ł͂قƂ�ǂ̕������g����B�f�[�^�̓p�[�T�ɂ���Đ��`����邱�ƂȂ��A���̋L�@�ɘA�ւ���A�v���P�[�V�����ɓn�����B�B��̗�O�́A SGML �I���^�O�̊J�n�����i < �j�ɂ��������Ďΐ��i / �j�ƃA���t�@�x�b�g������Ƃ�����p�[�T���F�����Ă��܂����Ƃł���B���̂悤�ȉˋ�̗�ł́A SGML �\���G���[���o�Ă��܂��B
<formula notation=tex>
\(E = mc^{2}</a\)
</formula>
�����킢�A���w�I�L�@�ɂ͎��ۂ� </ �̕��т�����邱�Ƃ͂قƂ�ǂȂ��B���ꂽ�ꍇ�̑Ώ��@�͖{���͈̔͊O�ł���i P3 �K�C�h���C�����Q�Ɓj�B
����́A���ꎩ�g�� SGML �ŏ����ꂽ�Z�p������ SGML �}�[�N�t��������ۂɖ��ɂȂ�B�������������ł́A�ᕶ���̃}�[�N�t���ƕ������̂��̂̃}�[�N�t���Ƃ��͂�����Ƌ�ʂ�����������A�I���^�O�̌����m�����������炾�B�ł���ʓI�ȉ����@�́A SGML �̗ᕶ���p�[�T�̉�͑ΏۊO�f�[�^�Ƃ��ċ�ʂ��邱�Ƃł���B���̗�̂悤�ɁA CDATA �}�[�N�ς݃Z�N�V���� (CDATA marked section) �Ƃ������ʂ� SGML �\���̒��ɓ���Ă��܂��̂ł���B
<p>A list should be encoded as follows:
<eg><![ CDATA [
<list>
<item>First item in the list</item>
<item>Second item</item>
</list>
]]>
</eg>
The <gi>list</gi> element consists of a series of <gi>item</gi>
elements.
���̗�ł́A <list> �v�f�́A�}�[�N�ς݃Z�N�V�����i���ʂȃ}�[�N�A�b�v�錾 <![ CDATA [ �Ŏn�܂� ]]> �ŏI���B�j�̒��ɖ��ߍ��܂�Ă��邽�߁A�������̂��̂̍\�������Ƃ͌��Ȃ���Ȃ��B
�e�L�X�g���� SGML �v�f���i���͑��̎��ʎq generic identifiers �j���Q�Ƃ���^�O <gi> �̎g�����ɂ����ӁB
�敪�̐���
����I�������Y�V�X�e���̂قƂ�ǂ́A���e�ꗗ������������������邱�Ƃ��ł���B TEI Lite �̘g�g�݂ɂ́A���̂悤�ɂ��Đ������ꂽ�Z�N�V������u���ꏊ���}�[�N�t������v�f������B
- <divGen> �v�f
- �e�L�X�g�����̃A�v���P�[�V�����ɂ���Ď����I�ɐ������ꂽ�e�L�X�g�敪�̌����ʒu�B
- type ����
- �������ꂽ�e�L�X�g�敪�̌^�i��F �����A�ꗗ�\���j�B�����l�̗�F index�i��������������A�����ɑ}�������B�j,toc�i�ڎ��E���e�ꗗ�j,figlist�i�}�̃��X�g�j,tablist�i�ꗗ�\�j ���B
<divGen> �v�f�́A�敪�v�f�̓��肤��Ƃ���Ȃ�ǂ��ɂł��u������ ���ł���B���̗�ł́A�������ꂽ�敪�̎�ނ��邽�߂� type �����̎g�������������Ă���B�ŏ��̗Ⴊ�ڎ��łQ�Ԗڂ������ł���B
<front> <titlePage> ... </titlePage> <divGen type=toc> <div type='Preface'><head>Preface</head> ... </div> </front> <body> ... </body> <back> <div1><head>Appendix</head> ... </div1> <divGen type=index n='Index'> </back>
�����������̍����E�ڎ�������̂ł͂Ȃ��}�[�N�t������ꍇ�ɂ́A�u12 ���X�g�v �ŐG�ꂽ <list> �v�f���g���ׂ��ł���B
�����̐���
�������^�O�t����ꂽ��������ڎ������邱�Ƃ͉�����Ȃ����������ł���̂����ʂ����A�ǎ��̍��������ɂ͂�蒍�Ӑ[���^�O�t�����K�v���B����̂����Ń^�O�t����ꂽ���ׂĂ̌���P�ɍ������ڂƂ��邾���ł͕s�\���ł���B�������A�Ⴆ�� <term> �v�f�� <name> �v�f�Ń}�[�N���������c�炸�E���グ��Ȃ�A���Ȃ�����炵�����̂ɂȂ��Ă���B
TEI DTD �ɂ́A�����Ƃ�����ƍ����쐬�̕��@�Ƃ��Ƀ}�[�N�t���ł��� <index> �Ƃ������ʂȃ^�O������B
- <index> �v�f
- ���������ꏊ�������B
- level1 ����
- �����̑�P����
- level2 ����
- �����̑�Q���ځi����B�ȉ������B�j
- level3 ����
- �����̑�R����
- level4 ����
- �����̑�S����
- index ����
- ���ڂ�����������������B
�Ⴆ�A���̐߂̑�Q�i���͎��̂悤�ɂȂ�B
... TEI lite also provides a special purpose <gi>index</gi> tag <index level1='indexing'> <index level1='index (tag)' level2='use in index generation'> which may be used ...
<index> �v�f�́A���߁E���͂̃^�O�ɂ��Ȃ�B�Ⴆ�A�I�r�f�B�E�X�̔�r���̘_�I�Ȍ��������邽�߂ɂ́A�l�����Ƃ̎��l�̌��y���ׂĂ��L�^���邱�Ƃ����߂��邩������Ȃ��B�w���^�����t�H�[�[�x�̒��̈ȉ��̍s�ł́A�W���s�^�[�i deus �y�� confiteor �̎��Ƃ��āj��Y���̌`�������W���s�^�[�i imago tauri fallacis �y�� teneo �̎��Ƃ��āj���̑��ւ̌��y���L�^���邱�ƂɂȂ�B ���̕��͂͋ߊ��� Willard McCarty, Burton Wright: An Analytical Onomasuticon to the Metamorphoses of Ovid, Princeton University Press) ��苖�Ĕ����������̂��B�@�����ł́A�����̒P�������{����Ă���B
<l n=3.001>iamque deus posita fallacis imagine tauri <l n=3.002>se confessus erat Dictaeaque rura tenebat
���߂̕K�v�́A�u�V ���L�v�Ř_���� <note> �v�f�A���邢�́u16 ���߁E���́v�ň����� <interp> �v�f���g�����ƂőΏ��ł��邩������Ȃ��B�����ł́A����� <index> �v�f���g�����Ƃɂ���Ă��������邱�Ƃ𖾂炩�ɂ��Ă������B
���̃I�u�W�F�N�g�������̍���������Ƃ��悤�B�P�͐_�̖��i dn : names of deities �j�A�Q�ڂ͌ꌹ�w�I�Q�Ɓi on : onomastic references �j�A�R�ڂ͑㖼���I�Q�Ɓi pr : pronominal references �j���̑��Ƃ������悤�ɁB�����́A���Ƃ�����ȕ��ɂȂ邾�낤�B
<l n=3.001>iamque deus posita fallacis imagine tauri
<index index="dn" level1="Iuppiter" level2="deus">
<index index="on" level1="Iuppiter (taurus)"
level2="imago tauri fallacis"></l>
<l n=3.002>se confessus erat Dictaeaque rura tenebat
<index index="pr" level1="Iuppiter" level2="se">
<index index="v" level1="Iuppiter" level2="confiteor (v227)">
<index index="mons" level1="Dicte" level2="rura Dictaea">
<index index="regio" level1="Creta" level2="rura Dictaea">
<index index="v" level1="Iuppiter (taurus)"
level2="teneo (v9)"></l>
����Ō���A�X�� <index> �v�f�̒��� level1 �����̒l�����o����ɂƂ邱�Ƃɂ���ēK�ȍ��������������B�����āA level2 �����̃L�[���[�h�ɂ͎�i�̌`�ň��p���ꂽ�P�ꂪ���ԁB���ۂ̎Q�Ƃ́A <index> �v�f�̏o��������ō����ɂƂ���B�����ł����A <index> ���܂� <l> �v�f�̎��ʎq������ł���B
18�@�����R�[�h�A�����i�A�N�Z���g�j�L���A���̑�
���[���b�p��������g�p����҂ɂƂ��āA�����R�[�h�̎g�p�Ɋւ��� TEI �����͒P���Ȃ��̂ł���B���[�J���Ɏg������A�����̋@�B�Ȃ�\�t�g�Ȃ�̃T�|�[�g���镶���R�[�h���g���悢�B�������ꕶ����łL�[���s��������A���ȗ��ɃL�[�{�[�h���J�X�^�}�C�Y����悢�i�Ⴆ�A�A�N�Z���g������\�����߂ɁA�K���ȃA�N�Z���g�L�[���L�[�̒���ɑłB���邢�́A aE �� ä ��\���Ƃ����悤�ɁA�ʏ�̕��͂ɂ͌��ꂻ�����Ȃ������̑g�ݍ��킹���g���đł��j�B�������Ďg���������͂��Ƃňꊇ�u���ɂ���Đ����������ɉ��߂邱�Ƃ��ł���B
�����e���������g���Ă�����A���Ȃ̕���ŕW������@������ꍇ�Ȃǂ͂�����g���悢�B����͔��\�ł���B����͕��ʂɕM�L�Ŏg����삵����@���@�̗ނ̚��O�ƂȂ���F���B�����āA���̕��@�͂������̍��� (ligatures) �E������ (ties) �E�����k�A�N�Z���g�l�L�� (diacritics) ������Ȃ��̂ł���A���ɗL�p�Ȃ��̂ɂȂ邾�낤�B
�قȂ�V�X�e���ԂŃt�@�C������������ɂ́A�d�q�I�Ȍ����ɍۂ��Ă��قƂ�Ǖς�邱�Ƃ̂Ȃ����̕����̂ق��� SGML �̎��̎Q�� (entitiy references) ���g���Ēu��������悢�B
a b c d e f g h i j k l m n o p q r s t u v w x y z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 0 1 2 3 4 5 6 7 8 9 " % & ' ( ) * + , - . / : ; < = > ? _ (space)
���̃��X�g����́A���̕����������Ă���B�����̕����́A������W�����z�����L�͂ȃl�b�g���[�N�ɂ����Ă͎��ɂ悭�����������N�����ă��[�U������������̂Ȃ̂��B������Ǝ茳�� Mac ���� PC �@�Ƀf�[�^��]�����邭�炢�Ȃ�A�܂����v���B
! # $ [ \ ] ^ ` { } | ~
��ƊԂ̃l�b�g���[�N�Ő���ȃf�[�^�]�����m�ۂ��邽�߁A�A�N�Z���g������g�����e�������A�e�������A�]���̃L�[�{�[�h�ɂȂ��V���{�������Ȃǂ͂��ׂĎ��̎Q�Ƃ�p���ĕ\�����Ȃ���Ȃ�Ȃ��B
�W���I�� SGML ���̐錾���s���A TEI �����̕����t�@�C���ɓƎ��� SGML ���̖����g�����Ƃ��ł���B�������A�W���I�Ȗ��O�͏璷�ł����m���̓_�ŗD��Ă���̂ŁA�\�����Ƃ��镶���͉p���b���҂Ȃ�\�������ł��A������ʂȃ��X�g���g��Ȃ��Ƃ��Q�Ƃ���Ă�����̕������킩��͂����B���̓_�́A���̕��@�ŃA�N�Z���g������\���ꍇ�ɂ͓��Ă͂܂�Ȃ��B
��Ɍf�����������u������������v���߂Ɏg�����̖��A�����̎�v����̃A�N�Z���g�����p�̎��̖��������̃��X�g�ɋ�����B SGML �֘A�̎d���ł͌��J���̕����Z�b�g�Ƃ��̓��e�ꗗ���g���B��q�̖��O�́A ISO �ɒ�߂����J���̕����Z�b�g�Ɋ�Â������̂ŁA�L���g���Ă��萄���ł�����̂��B
�K�v�ȕ��������̒��ɂȂ��ꍇ�A����Ɠ������A ISO ���J���̕����Z�b�g�ō̂��Ă���̂Ɠ��������@���g���ĕ������̂����Ă悢�B
- digraphs
- ��d�����B���̕����ɕ����� lig (ligature) ��t���Ď��̖������B�啶���ɑ��������͑啶���ƂȂ�B�i���̖��ł͑啶���E����������ʂ���B�j��F aelig (æ) ,AElig (Æ) ,szlig (ß)�B
- diacritics and accents
- �A�N�Z���g�L���E�����L���B�����̌���ł́A���̕�������A�N�Z���g���������ɕt���Ď��̖���\���B�啶���܂��͏������B
- umlaut
- �E�����E�g�A�g���}�B��Fauml (ä) , Auml (Ä) , euml (ë) , iuml ( ï �|�}�}) , ouml (ö) , Ouml (Ö) , uuml (ü) , Uuml (Ü)�B
- acute
- �s�i�g���j�A�N�Z���g (´ ) �A�����A�N�Z���g�B��F aacute (á) , eacute (é) , Eacute (É) , iacute ( í ) , oacute (ó) , uacute (ú) �B
- grave
- �}���A�N�Z���g�i�M�j�B��F agrave (à) , egrave (è) , igrave ( ì ) , ugrave (ù) �B
- circumflex
- �Ȑ܁i�ϒ��j�A�N�Z���g�i�O�j�B��F acirc (â) , ecirc (ê) , Ecirc (Ê) , icirc ( î ) , ocirc (ô) , ucirc (û) �B
- tilde
- �`���_�i~�j�B��F atilde (ã) , Atilde (Ã) , ntilde (ñ) , Ntilde (Ñ) , otilde (õ) , Otilde (Õ) �B
- consonants
- �q���B�ȉ��̗�́A��������Ɍ��������Ȏq���ɑ�����̖��ł���B�Z�f�B�[�� ccedil (ç) , Ccedil (Ç) , eth (ð) , ETH ( Ð ) , thorn (þ) , THORN (Þ) , �G�X�c�F�b�g szlig (ß) �B
- punctuation marks
- ��Ǔ_�B��F ldquo (“) , rdquo (”) , lsquo (‘) , rsquo (’) , mdash (—�@�S�p�P�������̃_�b�V���k one-em dash �l) , hellip (… �@�ȗ������k horizontal ellipsis �l) �B�i�����́u���������v���镶���̃��X�g���Q�ƁB�j
- �u���������v���镶��
- �ȏ�̕\���̒��ɂ��A���݂̃C���^�[�l�b�g�Łu���������v���邩������Ȃ�����������A���̎��̂ɂ���ĕ\�����Ă��悢�B excl ( ! ) , num (#) , dollar ($) , lsqb ( [ ) , rsqb ( ] ) , bsol (\) , circ ( ˆ ) , lsquo ( ‘ ) , grave , lcub ( { ) , rcub ( } ), verbar ( / ) , tilde (~) �B
19�@�O���E��t
�O��
�̖̂{�ɂ͂悭�A���E�O�u���Ƃ��Ă̏��ȂȂǂ������āA�{���ȊO�Ɍ���E�Љ�ʂ̒m������Ă����B TEI P3 �K�C�h���C���ɂ́A�O���Ɍ��܂��Č����e�L�X�g�v�f����ʂ�����@���o�Ă��邪�A�����ɂ������Z�ɂ܂Ƃ߂�B
�y���z
�����̔��́A <titlePage> �v�f�Ŏ����B���̒��̕��͂��A�ȉ�����ӂ��킵���v�f�Ń}�[�N�t������B
- <titlePage> �v�f
- �O���E��t�̔��B
- <docTitle> �v�f
- ���ɂ��镶���̑薼�B�S�̂̓��e���������́B����� <titlePart> �v�f�ɍו�����B
- <titlePart> �v�f
- ���ɂ��镶���̊e�͐߁B�܂��A�������E���쌠�i�A���j�\���ȊO�œ��ɏꏊ�����܂��Ă��Ȃ����͂ɂ��K�p�ł���B
- type ����
- �e�͐߂̖����B�����̗�F main �i���j,sub �i����j,desc �i���̌��������kdescriptive paraphrase�l) ,alt �i����̑�kalternative title�l�j���B
- <byline> �v�f
- ���܂��͍Ō�ɂ���i��\�j���M�Җ��B
- <docAuthor> �v�f
- ���ɂ��镶���̒��Җ��B <byline> �v�f�Ɋ܂܂�邪�A�܂܂�Ȃ����Ƃ�����B
- <docDate> �v�f
- �����ɂ��镶���̓��t�B
- <docEdition> �v�f
- ���ɂ���o�ŗ����B
- <docImprint> �v�f
- ���������ɂ������̋L�q�i�o�Œn�E������t�E���s���j�B
- <epigraph> �v�f
- �莫�E����B�͐߂̏��߁E�����ɂ�����p�B�i�o�T�̋L�q����E�Ȃ��B�j
�����̋�ʂ��K�v�ȏꍇ�A�O�q�̂悤�� rend ������p����B�������A������̎��ԃX�y�[�X�⎚�̃T�C�Y�Ȃǂ��܂�ׂ����_�܂ł́A�܂��K�C�h���C���ɒ�߂Ă��Ȃ��B����̎�ʂ́A lang �����܂��� <foreign> �v�f��K�X�g���B���O�́A�����ł� <name> �v�f��p���ă^�O�t������B
�����^�O�t�������Q�̗�F
<titlePage rend=Roman>
<docTitle><titlePart type=main>
PARADISE REGAIN'D. A POEM In IV <hi>BOOKS</hi>.
</titlePart>
<titlePart>
To which is added <title>SAMSON AGONISTES</title>.
</titlePart>
</docTitle>
<byLine>The Author <docAuthor>JOHN MILTON</docAuthor></byline>
<docImprint><name>LONDON</name>,
Printed by <name>J.M.</name>
for <name>John Starkey</name>
at the <name>Mitre</name>
in <name>Fleetstreet</name>,
near <name>Temple-Bar.</name>
</docImprint>
<docDate>MDCLXXI</docDate>
</titlePage>
<titlePage>
<docTitle><titlePart type=main>
Lives of the Queens of England, from the Norman
Conquest;</titlePart>
<titlePart type='sub'>with anecdotes of their courts.
</titlePart></docTitle>
<titlePart>Now first published from Official Records
and other authentic documents private as well as
public.</titlePart>
<docEdition>New edition, with corrections and
additions</docEdition>
<byline>By <docAuthor>Agnes Strickland</docAuthor></byline>
<epigraph>
<q>The treasures of antiquity laid up in old
historic rolls, I opened.</q>
<bibl>BEAUMONT</bibl>
</epigraph>
<docImprint>Philadelphia: Blanchard and Lea</docImprint>
<docDate>1860.</docDate>
</titlePage>
�y�O���z
�O���̎�ȃe�L�X�g�E�u���b�N�́A <div> �v�f�� <div1> �Ń}�[�N�t������B���ɋ�����̂́A type �����̒l�����A����ɂ���đO���ɋ��ʂ������܂��܂ȃ^�C�v����ʂ��邱�Ƃ��ł���B
- foreword
- �����B���Ȃ̌`���ȂǂŒ��ҁE�ҎҁE�o�Ŏ҂��ǎ҂Ɉ��Ăď��������́B
- preface
- �i����j
- dedication
- �����B�ǎ҈ȊO�̓���l���Ɍ������i�莆�`�����́j���́B���҂����̍�i�𐄑E����Ƃ������̂������B
- abstract
- �����B��i�̓��e��v�����́B
- ack (acknowledgements)
- ���A�E�ӎ��B
- contents
- �ڎ��B�������� <list> �v�f�Ń^�O�t������B
- frontispiece
- ���G�B���������܂߂�B
���̃e�L�X�g�����Ɠ������A�O���ł͂����͍\���I�ȗv�f�͖������A�����Ă����̖����͏������B���ʁA head �v�f�Ŋ����邠���̌��o���E�薼�Ŏn�܂�B���Ȃ̏ꍇ�́A���̕t���v�f���܂ށB
- <salute> �v�f
- ���A�E����i����j�B�����E�������̑O�A���邢�͏��ȁE�����̌��тɒu�����B
- <signed> �v�f
- �����B�����E�������̌��т̈��A�B
- <byline> �v�f
- ���A����ɂ���M�ҁi��ҁj���̋L�ځB
- <dateline> �v�f
- ���ȁE�V���A�ڂȂǂ̏��߁i�I���j�Ɂi���o���E����\���̂悤�ȈӖ������Łj�u���쐬�����E�ꏊ���̑��̋L�q�B
- <argument> �v�f
- �[�T�E�v�|�B���̈�߂ŏq�ׂĂ���_��̉ӏ������E�v��B
- <cit> �v�f
- ���̕�������̈��p�B�o�T�̏��������܂ށB
- <opener> �v�f
- �����B���ȂȂǂ̏��߂ɒu���A��L dateline, byline, salutation �̗ނ̃O���[�v�B
- <closer> �v�f
- ��t�B���ȂȂǂ̏I���ɒu���A��L dateline, byline, salutation �̗ނ̃O���[�v�B
�{���̊e���ɒu����鏑�Ȃ��A��������v�f�����B
�~���g���́w�R�[�}�X�x�����̌������^�O�t��������������B
<div type='dedication'> <head>To the Right Honourable <name>JOHN Lord Viscount BRACLY</name>, Son and Heir apparent to the Earl of Bridgewater, &c.</head> <salute>MY LORD,</salute> <p>THis <hi>Poem</hi>, which receiv'd its first occasion of Birth from your Self, and others of your Noble Family .... and as in this representation your attendant <name>Thyrsis</name>, so now in all reall expression <closer> <salute>Your faithfull, and most humble servant</salute> <signed><name>H. LAWES.</name></signed> </closer> </div>
��t
�y��t�̍\���敪�z
�o�ł̎��ۂ͂��܂��܂ł���A��t�͑O���̍��ŋ������قƂ�ǂ��ׂĂ̗v�f���܂ށB�����āA��t�͈ȉ��Ɏ������̂� <back> �v�f�Ɋ܂߂Ă悢�B�����͖{���̍\���敪���l�ɁA <div> �v�f�܂��� <div1> �v�f�Ƃ��ă^�O�t�����A type �����ɂ���ċ�ʂ���̂��悢�B
- appendix
- �t�^�B
- glossary
- �p��W�E��`�W�B�ʏ�A type=gloss �̌`�����Ƃ�B
- notes
- <note> �v�f�̂Ȃ�сB
- bibliography
- �������B�ʏ�A��p�� <listBibl> �v�f�̒��ɁA�e���ڂ� <bibl> �v�f�ł܂Ƃ߂ĕ��ׂ�B
- index
- �����B���̍\�������������X�g���p��W�̌`�����Ƃ�B <head> �v�f��u������A�O�u���E�㏑���������肷�邱�Ƃ��ł���B�i TEI P3 �K�C�h���C���ł́A�����쐬�̍ۂɍ��������邽�߂̓��ʂȗv�f���߂Ă���B�u17 �����̐����v���Q�ƁB�j
- colophon
- ���t�B�����̌��Ɉ���̏ꏊ�E���������҂��L�������́B����̏��Ђł́A�悭�o�ł̏ڍׂ⊈���ʂ̐��������Ă���B
20�@ TEI �w�b�_
���ł̔��ɂ���悤�ȏ��\���̕��͂́A TEI �����̃e�L�X�g�ł̓w�b�_�̒��ɋL�q����B�w�b�_�́A <teiHeader> �v�f�Ŏn�܂�A�S�̎�v�������琬��B
- <fileDesc> �v�f
- �d�q�������t�@�C���̏����I�L�q���܂Ƃ߂�B
- <encodingDesc> �v�f
- �d�q�e�L�X�g�Ƃ��̌��ɂȂ镶���̊W���܂Ƃ߂�B
- <profileDesc> �v�f
- �d�q�e�L�X�g�̏����I�L�q�ȊO�̎������ڍׂɏq�ׂ�B���ɁA�g�p����i������j�̎�ށA�O������g���ꍇ�̐����A�W�ҁA�w�i���B
- <revisionDesc> �v�f
- �t�@�C���̍X�V�������Ȍ��ɂ܂Ƃ߂�B
�R�[�p�X����ږ{�́A��i�e�̓���������A�R�[�p�X�S�̂̃w�b�_�ƌX�̍�i�̃w�b�_�������Ă悢�B���̎��A�w�b�_�̃^�C�v�� type �����ŕ\���B���̗�́A�R�[�p�X�E���x���̃w�b�_�ł���B
<teiHeader type=corpus>
�w�b�_�̗v�f�ɂ́A��ȏ�� <p> �v�f���琬����̂�����A���̂悤�ɃO���[�v���������̂�����B
- ���O�̖����� Stmt (statement) �ɂȂ�v�f�B�\���I�ȏ����L�^�����v�f�̏W���ȂǁB
- ���O�̖����� Decl (declaration) �ɂȂ�v�f�B���ʂȃ}�[�N�t���ɂ��Ă̏��B
- ���O�̖����� Desc (description) �ɂȂ�v�f�B���ʂ̕��́B
�t�@�C�����
<fileDesc> �v�f�͕K�{�ł���B���̗v�f���g���ĕ����t�@�C���̏����I�L�q���܂Ƃ߂�B
- <titleStmt> (title statement) �v�f
- ��i�̕W��E��蓙�B
- <editionStmt> �v�f
- �e�L�X�g�̊e�ł̏��B
- <extent> �v�f
- ���}�̂ɓK�X�̒P�ʂœ��ꂽ�Ƃ��̓d�q�e�L�X�g�̃T�C�Y�B
- <publicationStmt> �v�f
- �d�q�e�L�X�g���̑��̏o�ŁE�z�z�Ɋւ�����B
- <seriesStmt> �v�f
- �p�����̈ꕔ�ł���ꍇ�A���̏��B
- <notesStmt> �v�f
- �����I�L�q�̑��̊o���������W�߂����́B
- <sourceDesc> �v�f
- �d�q�e�L�X�g�̌����Ɋւ��鏑���I�L�q�B
�ł��ȒP�ȃw�b�_�̍\���F
<teiHeader>
<fileDesc>
<titleStmt> ... </titleStmt>
<publicationStmt> ... <publicationStmt>
<sourceDesc> ... <sourceDesc>
</fileDesc>
</teiHeader>
�y�W��z
<titleStmt> �v�f�ɂ́A���̗v�f���g����B
- <title> �v�f
- ��i�̕W��B�L���E���ЁE�V���E�p�����̑�܂��͕���B
- <author> �v�f
- �����I�ȎQ�Ƃ̒��ł̒��ҁi�l�E�g�D�j�B�Q�l���ڂ̒��ł̒���ґ�\�B
- <sponsor> �v�f
- �X�|���T�[�ƂȂ�g�D�E�@�ւ̖��O�B
- <funder> �v�f
- �v���W�F�N�g�A�����̎����Җ��i�l�E�g�D�E�@�ցj�B
- <principal> �v�f
- �d�q�e�L�X�g�̐���ӔC�Җ��B
- <respStmt> �v�f
- �����E�o�ŁE�L�^�E�p�����̒m�I���e�̐ӔC�҂̒��쌠�\���B���ҁE�ҏW�ғ��̗v�f�ɂ͓��Ă͂܂�Ȃ����́B
���̂悤�ɁA�W��̓R���s���[�^�̃t�@�C���ƌ����Ƃŋ�ʂ���̂��]�܂����B
[title of source]: a machine readable transcription [title of source]: electronic edition A machine readable version of: [title of source]
<respStmt> �v�f�́A���̕��v�f���܂ށB�i������Q�ƁB�j
- <resp> �v�f
- �l�̒m�I�ӔC�̐������L������B
- <name> �v�f
- �ŗL�����E�����傪����B
<titleStmt>
<title>Two stories by Edgar Allen Poe: a machine readable
transcription</title>
<author>Poe, Edgar Allen (1809-1849)
<respStmt><resp>compiled by</resp>
<name>James D. Benson</name></respStmt>
</titleStmt>
�y�ŗ��z
<editionStmt> �v�f�́A�����̒��� <edition> �v�f���g���Ă��鎞�A�ł��Ƃ̏����܂Ƃ߂�B�ȉ��̗v�f���܂܂��B
- <edition> �v�f
- �e�L�X�g�̈�̔ł̓������L���B
- <respStmt> �v�f
- �����E�o�ŁE�L�^�E�p�����̒m�I���e�̐ӔC�҂̒��쌠�\���B���ҁE�ҏW�ғ��̗v�f�ɂ͓��Ă͂܂�Ȃ����́B
��̗�F
<editionStmt>
<edition n=U2>Third draft, substantially revised
<date>1987</date>
</edition>
</editionStmt>
�d�q�e�L�X�g�̔ł��ǂ����߂邩�́A�}�[�N�t���S���҂ɔC�����B
�y�T�C�Y�z
<extent> �v�f�́A�t�@�C���̃T�C�Y�������B
<extent>4532 bytes</extent>
�y�o�Łz
<publicationStmt> �v�f�͕K�{�ł���B�ȉ��̂悤�ȋL�q�܂��͗v�f�O���[�v���܂܂��B
- <publisher> �v�f
- �o�ŁE�z�z���̑g�D���B
- <distributor> �v�f
- �e�L�X�g�̔z�z�ӔC�҂܂��͑㗝�@�ցB
- <authority> �v�f
- �o�ŁE�z�z���ȊO�ɓd�q�e�L�X�g������ӔC�҂܂��͑㗝�@�ցB
�o�ł̋L�ڂ������I�ɏ�����Ă���ꍇ�ȊO�́A���̂R�v�f�̂ǂꂩ���g���B�����ɂ́A���̗v�f�������B
- <pubPlace> �v�f
- �o�Œn�B
- <address> �v�f
- �o�Ŏҁi�g�D�E�l�j�̏Z���i�A�h���X�j�B
- <idno> �v�f
- �����̎��� id �B�i�W�����̗L���ɂ������Ȃ��B�j
- type ����
- ISBN ���A�ԍ��̗ޕʂ��L���B
- <availability> �v�f
- �e�L�X�g�̗��p�K��B�g�p�E�z�z�ɓ������Ă̐����⒘�쌠�ȂǁB
- status ����
- ���݂̗��p���Ɋւ���R�[�h�B�l�̗�F restricted,unknown,free ���B
- <date> �v�f
- ���t�B
<publicationStmt>
<publisher>Oxford University Press</publisher>
<pubPlace>Oxford</pubPlace> <date>1989</date>
<idno type=ISBN> 0-19-254705-5</idno>
<availability>Copyright 1989, Oxford University
Press</availability>
</publicationStmt>
�y�p���E�o���z
<seriesStmt> �v�f�́A�o�ŕ����p���ɂ���ꍇ�A���̏����܂Ƃ߂�B <title> �v�f�A <idno> �v�f�A <respStmt> �v�f������B
<notesStmt> �v�f���g���ꍇ�A���L�E���߂��܂� <note> �v�f���܂܂��B�`���I�ȎQ�l�����ł̒��ߗ̈�ɂ��ẮA TEI �̘g�g�݂Ő�p�̗v�f�����蓖�ĂĂ���B
�y�T���z
<sourceDesc> �v�f�́A�R���s���[�^�E�t�@�C���̌��ɂȂ������T�̏ڍׂ��L�^����K�{�̗v�f�ł���B�����̐����ł�������A�����I�Ȉ��p�������肷�邪�A���̍ێ��̗v�f���g���B
- <bibl> �v�f
- �ɂ₩�ȍ\���������������I���p�B�����Ƀ^�O���g�����Ƃ��g��Ȃ����Ƃ�����B
- <biblFull> �v�f
- TEI �t�@�C���̋L�q�̂��ׂĂ̍\���v�f�����銮�S�ȍ\���������������I���p�B
- <listBibl> �v�f
- ���ׂĂ̏����I���p�̃��X�g�B
��̗�F
<sourceDesc>
<bibl>The first folio of Shakespeare, prepared by Charlton
Hinman (The Norton Facsimile, 1968)</bibl>
</sourceDesc>
<sourceDesc>
<scriptStmt id=CNN12>
<bibl><author>CNN Network News
<title>News headlines
<date>12 Jun 1989
</bibl>
</scriptStmt>
</sourceDesc>
�}�[�N�A�b�v���
<encodingDesc> (encoding description) �v�f�́A�e�L�X�g�̎ʂ��S�̂ɋy�ԕ��@�ƕҏW�K����\���B���̃^�O�̎g�p�� TEI �ł͐������Ă���B�����ɂ́A�e�L�X�g�܂��͉��L�̗v�f���܂܂��B
- <projectDesc> �v�f
- �d�q�e�L�X�g�̃}�[�N�t���̖ړI�E�˂炢�B�e�L�X�g�̎��W�ߒ��ɂ��Ă̕K�v�ȏ����܂ށB
- <samplingDecl> �v�f
- �R�[�p�X����ڂ����ۂ̑I����j����@�B
- <editorialDecl> �v�f
- �}�[�N�t���̕��j�Ǝ���̏ڍׁB
- <tagsDecl> �v�f
- SGML �����Ɏg�����^�O�t���̏ڍׁB
- <refsDecl> �v�f
- �K�͓I�Q�Ƃ̍\���B
- <classDecl> �v�f
- �}�[�N�t���Ŏg�����ރR�[�h�̕��ފ�B
�y�ړI�E�I����j�z
<projectDesc> �v�f�� <samplingDecl> �v�f�̗�B
<encodingDesc>
<projectDesc>Texts collected for use in the Claremont
Shakespeare Clinic, June 1990.
</projectDesc>
</encodingDesc>
<encodingDesc>
<samplingDecl>Samples of 2000 words taken from the beginning
of the text
</samplingDecl>
</encodingDesc>
�y�}�[�N�A�b�v�錾�z
<editorialDecl> �v�f�́A�e�L�X�g���}�[�N�t����������\���B��T�A�ȉ��̏��_�ɂ킽��B�e�X�A�i������ƕ֗��ł���B
- correction �i�Z���j
- �Z�����j�B
- normalization �i�����͈́j
- ��������������͈́E���x�B
- quotation �i���p���j
- �����̈��p���̏��u�B�c�����A���̎Q�ƂŒu�������邩�A���p�J�n�����ƏI����������ʂ��邩�A�ȂǁB
- hyphenation �i�n�C�t�l�[�V�����j
- �����̃n�C�t���i���ɍs���j�̏��u�B�c�����A���̎Q�ƂŒu�������邩�A�ȂǁB
- segmentation �i���j
- �e�L�X�g�̋����B���E���߁E���f�w (graphemic strata) ���ɂ��B
- interpretation �i���߁j
- �e�L�X�g�̕��́E���߁B
��̗�F
<editorialDecl>
<p>The part of speech analysis applied throughout
section 4 was added by hand and has not been
checked.
<p>Errors in transcription controlled by using the
WordPerfect spelling checker.
<p>All words converted to Modern American spelling
using Webster's 9th Collegiate dictionary.
<p>All quotation marks converted to entity
references &odq; and &cdq;.
</editorialDecl>
�y�^�O�E�Q�ƁE���ރR�[�h�z
<tagsDecl> �v�f�́A�e�L�X�g���ɗp�����Ă��� SGML �^�O�̏���\���B�P���ȗv�f�ꗗ�Ȃ̂����A���̓��ʂȗv�f���g���B
- <tagUsage> �v�f
- TEI �����̕����͍ł��O���� <text> �v�f�����邪�A���̒��̗v�f�̎g�����ɂ��Ă����ɋL���B
- gi (generic identifier) ����
- ���̃^�O�ɂ���Ď������v�f�̖��i���̎��ʎq�j�B
- occurs ����
- �{�����ɂ��̗v�f������鐔�B
<rendition> �v�f�́A�����ŗv�f�̋�ʂ�\��������@��\���B
- <rendition> �v�f
- ����v�f����ɋ�ʂ��ĕ\�����邱�Ƃ�\���B
- <tagUsage> �v�f
- <text> ���̓���v�f�̎g�������L���B
- occurs ����
- ���̗v�f�̏o���x���B
- ident ����
- ���ʑ��� id �ɑ�������l�����v�f�̏o���x���B
- render ����
- <rendition> �v�f�̎��ʎq�B
��̗�F
<tagsDecl>
<tagUsage gi=text occurs=1>
<tagUsage gi=body occurs=1>
<tagUsage gi=p occurs=12>
<tagUsage gi=hi occurs=6>
</tagsDecl>
���́i�ˋ�́j�^�O�錾�́A�{����12�̒i���������Ă��āA���ɂU�� <hi> �v�f������ꍇ�̂��̂ł���B <tagsDecl> �v�f���g���ꍇ�A�֘A����e�L�X�g�v�f�Ŗ{���ɏo�Ă�����̂��ׂĂ� <tagUsage> �v�f�Ő������Ȃ���Ȃ�Ȃ��B
<refsDecl> �v�f�́A�^�O�t�����ꂽ�����ɕW���I�ȎQ�ƕ��@��g�ݍ��ޕ��@���������B�ł��ȒP�Ȃ̂́A���ׂĕ��͂ŋL�����Ƃł���B��̗�F
<refsDecl>
<p>The N attribute on each DIV1 and DIV2 contains the
canonical reference for each such division in the form
XX.yyy where XX is the book number in roman numeral and
yyy is the section number in arabic.
</refsDecl>
<classDecl> �v�f�́A�w�b�_�̑��̕����Ŏg���Ă���L�q�I�ȕ��ޕ��@�̒�`�E�o�����܂Ƃ߂���̂ł���B���̗v�f��p���čŒ�P�̕��ޖ@�������Ȃ���Ȃ�Ȃ��B
- <taxonomy> �v�f
- ���ޑ̌n�B�����I���p�ɂ���Ďw�����邩�A�܂��͍\���I�ȕ��ޑ̌n������B
- <bibl> �v�f
- ���₩�ȍ\���������������I���p�Ŏw������ꍇ�B�����I�\���v�f���}�[�N�t������Ă�����̂��A���Ȃ����̂�����B
- <category> �v�f
- ��ʕ��ނ�[�U��`�̕��ޑ̌n�Ɋ܂߂�ꂽ�X�̕��ލ��ځB
- <catDesc> �v�f
- ���ޑ̌n��e�L�X�g�ތ^���̕��ލ��ڂ�Z���̌`�ŏ��������́B
�ł��ȒP�ȗ�ł́A���̂悤�ɏ����I�Q�Ƃɂ���ĕ��ޑ̌n���`����B
<classDecl>
<taxonomy id='LCSH'>
<bibl>Library of Congress Subject Headings
</bibl>
</taxonomy>
</classDecl>
���Ɏ����悤�ɁA���ʂȖړI�̕��ޖ@����̑���ɁA�܂��͕t�������āA��`���Ă��悢�B
<taxonomy id=B>
<bibl>Brown Corpus</bibl>
<category id=B.A><catDesc>Press Reportage
<category id=B.A1><catDesc>Daily</category>
<category id=B.A2><catDesc>Sunday</category>
<category id=B.A3><catDesc>National</category>
<category id=B.A4><catDesc>Provincial</category>
<category id=B.A5><catDesc>Political</category>
<category id=B.A6><catDesc>Sports</category>
...
</category>
<category id=B.D><catDesc>Religion
<category id=B.D1><catDesc>Books</category>
<category id=B.D2><catDesc>Periodicals and tracts</category>
</category>
...
</taxonomy>
�����������ލ��ڂƓ���̃e�L�X�g�Ƃ������N��������@�ɂ��ẮA <textClass> �v�f���� <catRef> �v�f���g���i��q�j�B
�������
<profileDesc> �v�f�́A�e�L�X�g�̂��܂��܂ȋL�q�I���ʂ�����Â��������̘g�g�݂ŋL�^�ł���悤�ɂ���B�R�̕t���I�v�f������B
- <creation> �v�f
- �e�L�X�g�쐬�Ɋւ�����B
- <langUsage> �v�f
- �e�L�X�g�̌���E������E���W�X�^�E������������L�q�B
- <textClass> �v�f
- �e�L�X�g�̎��E������W���I�ȕ��ޖ@�E�V�\�[���X���ɏ]���ċL�������́B
��̗�F
<creation>
<date value='1992-08'>August 1992</date>
<name type=place>Taos, New Mexico</name>
</creation>
<textClass> �v�f�́A <classDecl> �v�f�ɂ���Ă��炩���ߒ�`���ꂽ�������Q�Ƃ��ăe�L�X�g�ނ���B���̗v�f���������܂ށB
- <keywords> �v�f
- �e�L�X�g�̐��������\���L�[���[�h�E���B
- scheme ����
- �L�[���[�h���`������b�W�̖��́B
- <classCode> �v�f
- �W���I�ȕ��ޖ@�ɂ��e�L�X�g�̕��ރR�[�h�B
- scheme ����
- �g�p���镪�ޕ��@�E�̌n�̖��́B
- <catRef> ����
- ���ޑ̌n��e�L�X�g�ތ^�Œ�`���ꂽ���ލ��ځi�����j�B
- target ����
- �֘A���镪�ލ��ځB
<keywords> �v�f�́A�e�L�X�g�̐��������\���L�[���[�h�E���̈ꗗ���܂ށB scheme �����ɂ��A������ <taxonomy> �v�f�Œ�`���ꂽ���ޑ̌n�Ƀ����N����B
<textClass>
<keywords scheme=LCSH>
<list>
<item>English literature -- History and criticism --
Data processing.</item>
<item>English literature -- History and criticism --
Theory etc.</item>
<item>English language -- Style -- Data
processing.</item>
</list>
</keywords>
</textClass>
�X�V����
<revisionDesc> �v�f�́A�e�L�X�g�̍X�V�L�^�i���O�j�ł���B�ȉ��̗v�f���܂� <change> �v�f�̕��т����̓��e�Ƃ���B
- <date> �v�f
- ���t�i�����͖��Ȃ��B�j
- <respStmt> �v�f
- ���ҁE�ҏW�ғ���p�̗v�f�ɊY�����Ȃ��A�e�L�X�g�̍X�V�E�L�^�̐ӔC�҂Ɋւ���L�^�B
- <item> �v�f
- ���X�g���ځB
��̗�F
<revisionDesc>
<change><date>6/3/91:</date>
<respStmt><name>EMB</name><resp>ed.</resp></respStmt>
<item>File format updated</item>
<change><date>5/25/90:</date>
<respSmt><name>EMB</name><resp>ed.</resp>
<item>Stuart's corrections entered</item>
</revisionDesc>
21�@�v�f���X�g
���ʑ���
TEI Lite �̕����^��`�i DTD �j�̗v�f�́A�ǂ���ȉ��̋��ʑ����������Ă���B
- ana
- �v�f�Ƃ��̉��߂Ƃ������N����B
- corresp
- �v�f�Ƒ��̑�������v�f�Ƃ������N����B
- id
- �v�f�����ʂ�����́B�A���t�@�x�b�g�����Ŏn�܂�A�����E�����E�n�C�t���E�s���I�h���܂ށB
- lang
- �v�f�̌���B���Ɏw�肪�Ȃ���A�{���Ɠ����B
- n
- �v�f�ԍ��B�ǂ�ȕ����̕��тł��悢�B�悭�Q�ƕ������L�^����̂Ɏg���B
- next
- �v�f���W���̒��̒���̗v�f�ƃ����N����B
- prev
- �v�f���W���̒����O�̗v�f�ƃ����N����B
- rend
- ���{�̗v�f�̑̍فi�C�^���b�N�́E���[�}���́E�f�B�X�v���C�����E�u���b�N�̓��B�l�͂ǂ�ȕ�����ł��悢�j�B
TEI Lite �̗v�f
���̃��X�g�́A TEI Lite DTD �̂��߂̗v�f���ׂĂɊȒP�Ȑ������������̂ł���B
- <abbr> [TOP OF LIST]
- �ȗ��`�B�W�J�`�� expan �����Ɏ����B
- <add>
- �t�����B���ҁE�M�L�ҁE�Z���ҁE���ߎғ����������������B
- <address>
- �o�ŎЁE�g�D�E�l���̏Z���E�A�h���X�B
- <addrLine>
- �Z���E�A�h���X�̂P�s�B
- <anchor>
- �������̎w���Ώۈʒu�i�|�C���g�j�������B
- <argument>
- �[�T�E�v�|�B���̈�߂ŏq�ׂĂ���_��̃��X�g�E�����B
- <author>
- �����I�Q�ƂŁA��i�̒��ҁi�l�E�g�D�j�������B���ׂĂ̎Q�l���ڂł̒��ґ�\�B
- <authority>
- �d�q�t�@�C���̍쐬�ӔC�҂܂��͑㗝�l�B�i�o�ŁE�z�z�҂������B�j
- <availability>
- �e�L�X�g�̗��p�Ɋւ�����B�g�p�E�z�z�̐����A���쌠���B
- <back>
- �{���̌�̕t�^���B
- <bibl>
- �ɂ₩�ȍ\���������������I���p�B�����v�f�̓^�O�t������Ă��Ȃ��Ƃ��悢�B
- <biblFull>
- ���S�ȍ\���������������I���p�B���ׂĂ̗v�f�� TEI �̃��[���ɏ]���ċL�q���Ă���B
- <biblScope>
- �����I�Q�Ƃ̋y�Ԕ͈́B�y�[�W�ԍ��̃��X�g�╪���`���̊e�҂ȂǁB
- <body>
- �P�̒P�ʂƂȂ�e�L�X�g�̂܂Ƃ܂�B�O���E��t�������B
- <byline>
- ��i�̔��E����̒��ŁA��i�̒����\�ӔC�҂������B
- <catDesc>
- ���ޑ̌n��e�L�X�g�ތ^�̕��ލ��ڂ�Z�����͂ŋL�q�������́B
- <category>
- ��ʂ̕��ލ��ڂ�[�U��`�̕��ޑ̌n�ɖ��ߍ��܂ꂽ�X�̕��ލ��ځB
- <catRef>
- ���ޑ̌n��e�L�X�g�ތ^�̕��ލ��ځi�P���E�����j���Q�Ƃ���B
- <cell>
- �\�̂P�̃Z���B
- <cit>
- �T���ւ̏����I�Q�Ƃ��Ƃ��Ȃ����������̈��p�B
- <classCode>
- �W���Ƃ������ޕ����ɂ���ăe�L�X�g�ނ����R�[�h�B scheme �����ɂ���ē��肷��B
- <classDecl>
- �e�L�X�g�Ɏg���镪�ރR�[�h���`�������ޑ̌n�i�P���E�����j���܂Ƃ߂�B
- <closer>
- ��t�B�i���Ɏ莆�́j�Ō�Ɍ���� dateline �A byline �A salutation ���̑��̌����܂Ƃ߂����́B
- <code>
- �`������i�v���O���~���O���ꓙ�j�̃R�[�h�̈ꕔ�B
- <corr> (correct)
- �����̌��Ǝv�����߂����߂��`�B
- <creation>
- �e�L�X�g�̍쐬�Ɋւ�����B
- <date> [TOP OF LIST]
- ���t�B�W���I�Ȓl�� value �����Ŏ����B
- <dateline>
- ���t�E���ԁE�ꏊ���B�莆�E�V���̓ǂݕ��E���̑��̃w�b�_�E��t�̂悤�Ȃ��̂Ƃ��đO�E��ɒu�������́B
- <del>
- ���ҁE�M�L�ҁE�Z���ҁE���ߎғ�����������폜���������E���E���́A�܂��͌����ō폜���Ă���|���L�ڂ�����A�����E�������₌��������肵�����́B
- <distributor>
- �e�L�X�g��z�z�����l�E�㗝�l�̖��O�B
- <div>
- �O���E�{���E��t�̓����̕��߁B
- <div1> … <div7>
- �O���E�{���E��t�̓����̑�P�`��V���x���̕��߁B
- <divGen>
- �e�L�X�g�����v���O�����ɂ���Ď����I�ɐ������ꂽ�e�L�X�g���߂̈ʒu�������B type �����ɂ���č����E�ڎ����̑��̋�ʂ�\���B
- <docAuthor>
- ���ɂ��镶���̒��Җ��B�i���� <byline> �̒��ɂ���킯�ł͂Ȃ��B�j
- <docDate>
- �i���������j���ɂ��镶���̓��t�B
- <docEdition>
- ���ɂ�����ŗ����B
- <docImprint>
- �i���������j�������ɂ������L�^�B�i�o�Œn�E�o�œ��E�o�Ŏҁj
- <docTitle>
- ���ɂ��镶���̕W��i���̍\���v�f���܂ށj�B����� <titlePart> �v�f�ɕ������B
- <edition>
- �e�L�X�g�̔ł��Ƃ̏ڍ��B
- <editionStmt>
- �P�̔łɊ֘A������̂܂Ƃ܂�B
- <editor>
- �Q�l���ڂŕҏW�ҁE�R���p�C���E�|��ғ��A�����҂Ɏ����ӔC���ҁi�l�E�g�D�E�@�ցj�B
- <editorialDecl>
- �e�L�X�g�̃}�[�N�t���ɍۂ��Ă̕ҏW�����E�葱���̏ڍׁB
- <eg>
- ��舵���Z�p�I���̊ȒP�ŒZ����B�R�[�h�̒f�Ђ� SGML �}�[�N�t���̗�ȂǁB
- <emph>
- ���@�I�E�C���I�ɋ����������\���B
- <encodingDesc>
- �d�q�e�L�X�g�ƌ����̊W���q�ׂ�B
- <epigraph>
- �莫�B�͐߂���̏��߂Ɍ�������p��B�i�o�T�̗L������Ȃ��B�j
- <extent>
- ���}�̂ɓK�X�̒P�ʂœ��ꂽ�Ƃ��̓d�q�e�L�X�g�̃T�C�Y�B
- <figure>
- �������ɃO���t�B�b�N�ߍ��ވʒu�������B�����́A�摜���̂��́i�� SGML �L�@�j���܂� SGML ���̂������B <figure> �v�f�̒��̒i���̓L���v�V������\���̂Ɏg���B
- <fileDesc>
- �d�q�t�@�C���̏����I�L�q���ׂāB
- <foreign>
- �e�L�X�g�{���ȊO�̌���ɑ�����������ʂ���B
- <formula>
- �� SGML �L�@�ŔC�ӂɕ\�������w�I�E�Ȋw�I�����B notation �����́A���̌������L������ SGML �L�@�̖��̂������B
- <front>
- �e�L�X�g���̂��̂��n�܂�O�ɒu���ꂽ�O���i�w�b�_�E���E�����E�������j�B
- <funder>
- �v���W�F�N�g��e�L�X�g�̎������B�Җ��i�l�E�g�D�E�@�ցj�B
- <gap> [TOP OF LIST]
- �ʖ{�̏ȗ������������B TEI �w�b�_�ɋL�q���ꂽ�ҏW��̎�̑I���ɂ����́A�܂��͌��{�����ǁi����j�ł��Ȃ����߂̂��́B
- <gi>
- ���ʂȎ��ʎq�B SGML ���̎��ʎq�A�܂��͗v�f���B
- <gloss>
- ������̒����E��`�ƂȂ���������B
- <group>
- �P��̕��܂��͕��͂̏W���B
- <head>
- ���o���B�߂̏����X�g�E�p��W�̌��o���ȂǁB
- <hi>
- ���ɍ\���I�ȗ��R���Ȃ��A���̖͂{���Ǝ��o�I�ɋ�ʂ������B
- <ident> (identifier)
- �����̎��ʎq�B�ϐ����E SGML �v�f���E�������ȂǁB
- <idno>
- �Q�l���ڂ����ʂ��邽�߂̔ԍ��i��͖��Ȃ��j�B type �����ł��̎��ʕ�������\���B
- <imprint>
- �Q�l���ڂ̏o�ŁE�z�z�Ɋւ�������܂Ƃ߂����́B
- <index>
- ������������̈ʒu���}�[�N����B�����́A��Ȍ`�A����l���x���̌��������ɓ���邽�߂Ɏg���B
- <interp>
- �e�L�X�g�̌��ƃ����N�\�Ȓ��߁B�����ɂ́A resp, type, value ������B
- <interpGrp>
- <interp> �^�O���W�߂����́B
- <item>
- ���X�g���ځB
- <keywords> [TOP OF LIST]
- �e�L�X�g�̎��������肷��L�[���[�h����̃��X�g�B�L�[���[�h���i�V�\�[���X�ł́j������Ȃ�A����� scheme �����Ŏ��ʂ����B
- <kw>
- �`������̃L�[���[�h�B
- <l>
- �C���́i�����炭�s���S�ȁj�P�s�B
- <label>
- ���X�g���ڂƊ֘A�������x���B�p��W�ł͒�`��������w���B
- <langUsage>
- �e�L�X�g�ɕ\���ꂽ����E������E���W�X�^�E�������B
- <lb>
- ����̔Łi���j�̃e�L�X�g�ł̐V�����i�����́j�s�̎n�܂�B
- <list>
- �ԍ��t���E�ԍ��Ȃ��A���̑����X�g�̌`�ŕ��ׂ����ڂ̘A�Ȃ�B
- <listBibl>
- ���ׂĂ̏����I���p�̃��X�g�B
- <mentioned> [TOP OF LIST]
- ���y���ꂽ�����Ŏg���Ă��Ȃ����������B
- <milestone>
- �W���ƂȂ�Q�ƕ����̕ω��ɂ���Ď������e�L�X�g�̐߂̋��E�B�����ɂ́A ed (edition) �A unit (page ���̑�) �A n (new value) �Ȃǂ�����B
- <name>
- �ŗL�����i��j�B�������g���āA���̎�ނ���������A�W���I�Ȍ�`���L������A�Ǝ��̎��ʎq�ɂ�����l�╨�Ɗ֘A�Â����肷�邱�Ƃ��ł���B
- <note>
- ���L�E���߁B�����ɂ��A���L�̎�ށE�ʒu�E�T�����������B
- <notesStmt>
- �⒍�B�����I�L�q�̏��ɉ����ăe�L�X�g�Ɋւ��钍�L���W�߂����́B
- <num>
- �����E�ԍ��B��������Ȃ��B�W���I�Ȓl�� value �����Ŏ����B
- <opener>
- ���߂̏��߁i���Ɏ莆�̍ŏ��j�ɒu�� dateline �A byline �A salutation �̗ނ̋�̏W���B
- <orig> (original form)
- �����ł̓ǂݕ��B���K�������`�́A reg (regularized form) �����ŕ\���B
- <p> [TOP OF LIST]
- �U���̒i���i�p���O���t�j�B
- <pb>
- �W���Ƃ����Q�ƕ����ł̃y�[�W�̋��ځB
- <principal>
- �d�q�e�L�X�g�̍쐬�ɂ������Ă̑�\�����Җ��B
- <profileDesc>
- �e�L�X�g�̔��I�ȑ��ʂ��ڍׂɋL�q�������́B���Ɍ���╛����A�e�L�X�g�̐��ݏo���ꂽ�A�W�҂Ƃ��̔w�i�ȂǁB
- <projectDesc>
- �d�q�e�L�X�g�t�@�C�����}�[�N�t�������ړI�E�˂炢���ڍׂɋL�q�������́B�����ăe�L�X�g�����W�����ߒ��Ɋւ���֘A����\���B
- <ptr>
- �|�C���^�B���ʉ\�ȗv�f�i�P���E�����j�ɂ���Č��݂̕����̑��̏ꏊ���w�����������́B
- <publicationStmt>
- �d�q�e�L�X�g���̑��̏o�ŁE�z�z�Ɋւ�����̏W���B
- <publisher>
- �o�ŎЁB�Q�l���ڂ̏o�ŁE�z�z�̑�\�g�D���B
- <pubPlace>
- �Q�l���ڂ̏o�Œn���B
- <q>
- ���p�E���p�炵�����́B
- <ref>
- �Q�ƁB���ʗv�f�i�P���E�����j�ɂ���āA���݂̕������̑��̏ꏊ���Q�Ƃ���B�e�L�X�g��R�����g���������`�ɂȂ��Ă���ꍇ������B�i�� ptr �C xref �j
- <refsDecl>
- �{���ɂ��ċK�͓I�Q�Ƃ��\��������@���L���B
- <reg>
- �ꉞ�u���K���E�W�����v���ꂽ�ǂݕ��B�����̓ǂݕ��́A orig �����Ŏ����B
- <rendition>
- �v�f�i�P���E�����j�̈Ӑ}�I�Ȏ��̕ύX���ɂ��Ă̏��B
- <resp>
- ���e���̐ӔC�E�ۏɂ��ďq�ׂ���B
- <respStmt>
- ���ҁE�ҏW�ғ��̐�p�v�f�ɂ͓��Ă͂܂�Ȃ����A�e�L�X�g�E�ҏW�E�L�^�E�p���Ҏ[���̑�\�҂ɂ��Ă��̐ӔC�E�ۏ��L�ڂ������́B
- <revisionDesc>
- �d�q�t�@�C���̍X�V�����B
- <row>
- �\�̂P�s�B
- <rs> (referring string)
- ���ړI�Ȗ��O�i���ޖ��́j��Q�ƌ��B�����ɂ́A���̌^�E�W���I�Ȍ`�E�Ǝ��̎��ʎq�ɂ�����l�i���j�Ƃ̊֘A�������B
- <s> (sentence unit) [TOP OF LIST]
- �����Ȃǂ̒P�ʂɕ��������́B�{���S�̂ɋy�ԒP���ȋK�͓I�Q�Ƃ��s�����߂ɗp����B
- <salute>
- ���A�E����i����j�B�����E�������̑��̃e�L�X�g�敪�̑O�A���邢�͏��ȁE�����̌��тɒu�����B
- <samplingDecl>
- �R�[�p�X��p����Ҏ[����ۂɃe�L�X�g�I����s���������ƕ��@���L�������́B
- <seg>
- �|�C���^�ŎQ�Ǝw���ł���悤�ɁA�������ɍ�����e�L�X�g�E�敪����肷��B type �����ɂ���ĕ��ނ���B
- <series>
- ������Q�l���ڂ��܂ޑp���̏��B
- <seriesStmt>
- �p���̏����܂Ƃ߂����́B
- <sic>
- �����̃}�}�B�s���m�Ɏv���錴���̎�������̂܂ʂ������́B
- <signed>
- �����E�������̑��̃e�L�X�g�敪�ɓY����ꂽ���т̈��A�E�����ȂǁB
- <soCalled>
- ������B���ҁE���肪�������p�� (scare quotes) ��C�^���b�N�̂��g���āA���e�͕ۏ̌���łȂ����Ƃ�\�������B
- <sourceDesc>
- �d�q�e�L�X�g�̌��ɂȂ��������̏����I�L�q�B
- <sp> (speech)
- �r�{�ł̉�b�B�܂��͎U���E�C���ł̉�b�����B�b����� who �����ŕ\���B
- <speaker>
- �r�{�̘b����̖��O���������ʂȌ`�̃w�b�_�A���x���B
- <sponsor>
- �i�d�q�e�L�X�g�쐬�v��́j�X�|���T�[�ƂȂ�g�D�E�@�ւ̖��́B
- <stage>
- �r�{���w�����s���g�����B
- <table>
- �\�B�s�Ɨ琬��ꗗ�\�`���̃e�L�X�g�B
- <tagsDecl>
- SGML �����ɉ�����^�O�t���ɂ��Ă̏ڍׁB�i�� tagUsage �j
- <tagUsage>
- TEI �����̕����ōł��O���� <text> �v�f���ł̓���̗v�f�̎g�p�@�������B�i�� tagsDecl �j
- <taxonomy>
- ���ޑ̌n�B�����I���p�ɂ���Ďw���ɑウ�邩�A�܂��͍\���I�ȕ��ޑ̌n�ɂ���Ė��������e�L�X�g�̗ތ^�B
- <term>
- ���p��Ƃ����i��A�́j���܂��͋L���ɂ���Ďw���������́B
- <textClass>
- �e�L�X�g�̎��E�������A�W���ƂȂ镪�ޕ����E�V�\�[���X���ɂ���ċL�q�������̏W���B
- <time>
- ���Ԃ�\�����B�����͖��Ȃ��B�W���I�Ȓl�́A value �����Ŏ����B
- <title>
- �_���E���ЁE�L���E�p�����̕W��B����ɑ����E������܂ށB
- <titlePage>
- �e�L�X�g�̔��y�[�W�B�O���������͌�t�̒��Ɍ����B
- <titlePart>
- ���Ɏ�������i�̕W����ו��������́B�����̕W��E���쌠�i�A���j�\�����ɂ͑������A���̎��R�ȏꏊ�ɒu�����B
- <titleStmt>
- ��i�̕W��Ƃ��̓��e�ۏɊւ�����i���j���܂Ƃ߂����́B
- <trailer>
- �I��茩�o���B�{���̍Ō�̐߂Ɍ���閖���̕W��E�t�b�^�B
- <unclear>
- ���ڂ̈ӁB���������ǁi�ǂݎ��j�s�\�ŁA�m�M���Ȃď����ʂ��Ȃ����E�i���B
- <xptr> [TOP OF LIST]
- ���݂̕������̑��̏ꏊ�A�܂��͊O���������w������|�C���^�B
- <xref>
- �Q�ƁB���ʗv�f�i�P���E�����j�ɂ���āA���݂̕������̑��̏ꏊ�A�܂��͊O���������w������|�C���^�B�e�L�X�g��R�����g���������`�ɂȂ��Ă���ꍇ������B�i�� ptr �C ref �j
22�@���t�@�����X
���̕t�^�ɂ́A SGML �Ɗ֘A���̏����I�Q�ƃ��X�g�������Ă���B�u13 �����I���p�v�ŏq�ׂ� <bibl> �v�f�̎g������������ɂ��Ȃ��Ă���B
<listBibl>
<bibl>
ALA (American Library Association).
<title>ALA-LC Romanization Tables: Transliteration Schemes
for Non-Roman Scripts</title>,
approved by the Library of Congress and the American Library
Association, tables compiled and edited by Randall K. Barry.
Washington: Library of Congress, 1991.
</bibl>
<bibl>ANSI (American National Standards Institute).
<title>ANSI X3.4-1986. American National Standard for
Information Systems --- Coded Character Sets --- 7-bit
American National Standard Code for Information
Interchange (7-bit ASCII).</title>
[New York]: ANSI, 1986.
</bibl>
<bibl>
<author>Barnard, David, et al.</author>
<title level=a>SGML-Based Markup for Literary Texts.</title>
<title>Computers and the Humanities</title>
<biblScope>22 (1988): 265-76.</biblScope>
</bibl>
<bibl>
<author>Barron, David</author>
<title level=a>Why use SGML?</title>
<title>Electronic Publishing
Origination, Dissemination and Design</title>
<biblScope>2.1 (April 1989): 3-24.</biblScope>
</bibl>
<bibl>
<author>Coombs, James H., Allen H. Renear, and
Steven J. DeRose.</author>
<title level=a>Markup Systems and the Future of
Scholarly Text Processing.</title>
<title>Communications of the ACM</title>
<biblScope>30.11 (November 1987): 933-947.</biblScope>
</bibl>
<bibl>
<editor>Cover, Robin C., et al.</editor>
<title>A Bibliography on Structured Text:
Technical Report 90-281</title>
<publisher>Queen's University,</publisher>
<pubPlace>Kingston, Ont.</pubPlace>
<date>June 1990</date>
<note place=inline>A current version of this bibliography
is maintained at
<code>http://www.sil.org/sgml/sgml.html</code>.
</bibl>
<bibl>
Goldfarb, Charles F.,
<title>The SGML Handbook.</title>
Oxford: Clarendon Press, 1990.
</bibl>
<bibl>
<author>van Herwijnen, Eric.</author>
<title>Practical SGML.</title>
<publisher>Kluwer Academic Publishers</publisher>
<date>1990; 2d ed. 1994.</date>
</bibl>
�i���M��w���H SGML �x���{�K�i���� 1992�j
<bibl>ISO (International Organization for
Standardization).
<title>ISO 8859-1: 1987 (E). Information processing
--- 8-bit Single-Byte Coded Graphic Character Sets ---
Part 1: Latin Alphabet No.1.</title>
(<title>Traitement de l'information --- Jeux de caracte
``res graphiques codés sur un seul octet ---
Partie 1: Alphabet latin no1.</title>)
First edition --- 1987-02-15. [Geneva]:
International Organization for Standardization, 1987.
</bibl>
<bibl>
ISO (International Organization for Standardization).
<title>ISO 8879-1986 (E). Information processing
--- Text and Office Systems --- Standard Generalized
Markup Language (SGML).</title>
First edition --- 1986-10-15. [Geneva]: International
Organization for Standardization, 1986.
</bibl>
<bibl>
ISO (International Organization for Standardization).
<title>ISO 8879:1986 / A1:1988 (E). Information
processing --- Text and Office Systems --- Standard
Generalized Markup Language (SGML), Amendment 1.</title>
Published 1988-07-01. [Geneva]:
International Organization for Standardization, 1988.
</bibl>
<bibl>
ISO (International Organization for Standardization).
<title>ISO/TR 9573-1988(E). Information processing
---SGML support facilities---Techniques for using SGML.
</title>
Final text of 1988-09-12.
</bibl>
<bibl>
ISO (International Organization for Standardization),
and IEC(International Electrotechnical Commission).
<title>ISO/IEC 10646-1:1993. Information technology
--- Universal Multiple-Octet Coded Character Set (UCS)
--- Part 1: Architecture and Basic Multilingual Plane.
</title>
[Geneva]: International Organization for
Standardization, 1993.
</bibl>
<bibl>ISO (International Organization for
Standardization), and IEC (International
Electrotechnical Commission).
<title>ISO/IEC 10744: 1992. Information
Technology --- Hypermedia/Time-based Structuring
Language (HyTime).</title>
[Geneva]: International Organization for
Standardization, 1992.
</bibl>
<bibl>
Langendoen, D. Terence, and Gary F. Simons.
<title level=a>A Rationale for the TEI
Recommendations for Feature-Structure Markup.
</title>
<title>Computers and the Humanities</title>
(1995; in press).
</bibl>
<bibl>
<author>Warmer, J., and S. van Egmond</author>
<title level=a>The implementation of the Amsterdam
SGML parser.</title>
<title>Electronic Publishing Origination,
Dissemination and Design</title>
<biblScope>2.2 (July 1989): 65-90.</biblScope>
</bibl>
</listBibl>