漢文エディタ
漢文エディタ2020に更新したので、ダウンロードファイルは、この注意書きのリンク先を参照してください。kanbun_editor_20140812.lzh
 紹介記事(pdf)
紹介記事(pdf)※ 2014年度以降の改善点は、こちらを参照。
☆変換例——縦書きHTMLを前提にしているので、現在縦書きに対応しているInternet Explorerで表示を確認してほしい。
【1】HTML「世説新語・巻1」
「聖徳太子伝暦・巻之上」
【2】MS-Word「世説新語・徳行1」
====================================================================================================
※ こちらはVersionUpしていない。過去のストックである。
Kanbun_Seikei.lzh(Kanbun_Seikei.bas)
・・・ MS-Wordにインポートする。kanbun_editor_20130330.xlsより、単体で変換可能になった。このスクリプトをWordにインポートする必要は無い。template_tate.lzh(template_tate.htm)
・・・ 縦書きHTMLの枠組みの一例====================================================================================================
【『漢文エディタ』の主な使い方】 同一の入力データから各種形式に変換。データの蓄積と随時利用ができる。
《関連画像は、このページ下部を参照。》
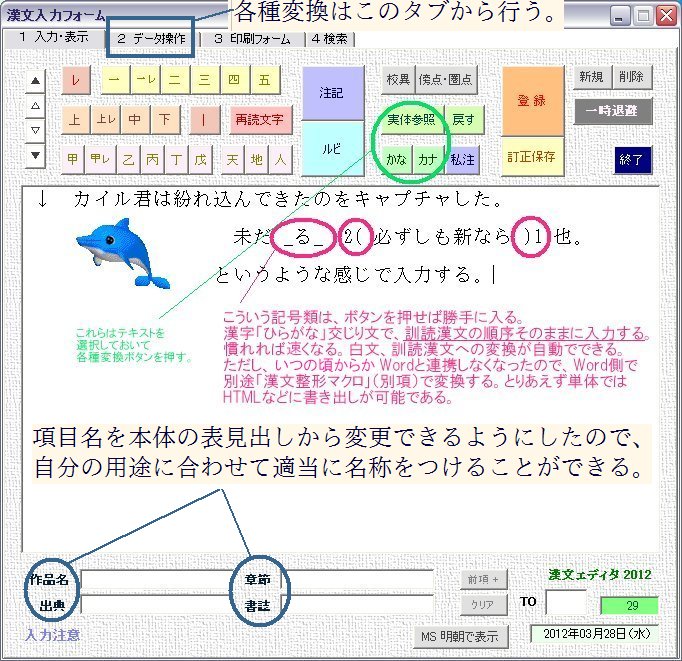
シート上の「漢文入力フォーム」ボタンをクリックして入力ウィンドウを表示。
上記ヘルプの入力方法を参照して、まずは入力し、ある程度の分量がまとまったら「登録」ボタンを押す。(くれぐれもESCボタンを2回押さないこと。フォームに入力した内容が消えてしまう。)
難字(環境依存文字)があるとメッセージが出るので、「?」の部分にその文字をもう一度入力して「訂正保存」ボタンを押す。そうすると再び「プロシージャの呼び出し、または引数が不正です」というエラーメッセージが出るので「終了」ではなく「デバッグ」ボタンを押す。(「終了」を押すとEXCELが見えなくなってしまう。)その時、VBエディタ画面になるので、上のツールバーから「■」アイコンの「リセット」ボタンを押す。それから「▶」(ユーザーフォームの実行)ボタンを押すと復帰する。面倒な手続きだが、難解字はきちんと入力されている。(または、漢文エディタ上で「文字実体参照」に変換して登録してもよいが、私は上記の方法で登録している。最後は、エディタMana2に書き出して自作スクリプト(ent_ref_NewGulim.vbs)で文字実体参照に再変換してShift-JISで保存している。)
〈起動〉〈入力〉〈保存〉の作業に合わせて、個別または全体のデータをバックアップするように工夫している。
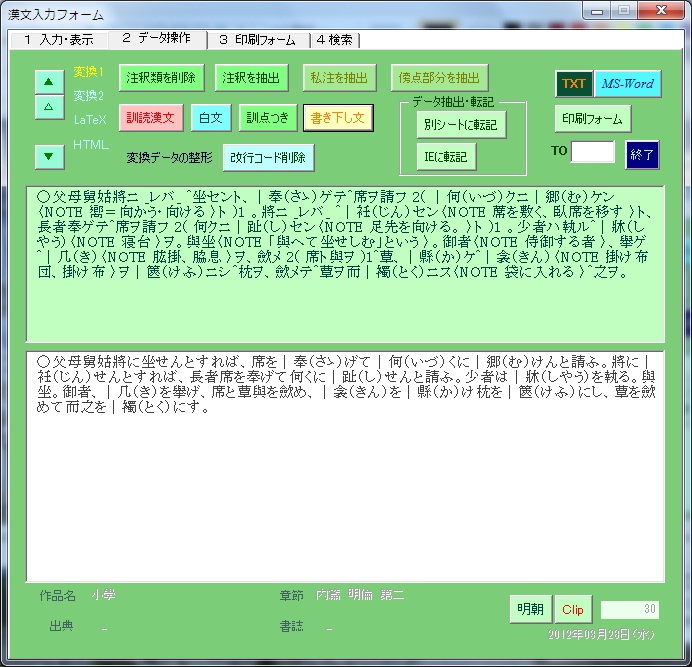
各種変換は、「データ操作」のタブから行う。
①白文(原文)は、「白文」ボタンを押す。
②訓読漢文は、「訓読漢文」ボタンを押す。→これはそのまま「MS-Word」ボタンでワードに書き出すとよい。
③書き下し文は、「書き下し文」ボタンを押す。
④縦書きHTMLへの書き出しは、「HTML」ラベルをクリックして「TAG(IE)」を押す。
→それぞれ変換したら、下の「Clip」ボタンでクリップボードに送り、エディタ等に貼り付けることができる。縦書きHTMLは、上記のような縦書き用の枠に貼り付けるとよい。(現在のところ、対応ブラウザはtrident layout engineを利用したIEかLunaScapeになってしまう。)
その他、データの検索・結合・印刷・新旧字体や平仮名カタカナの相互変換・ワードとの連携はもとよりテキストファイルやTEXへの書き出し等、いろいろなことが可能である。
データは(MyDocument等に)日付フォルダを作り、バックアップするほか、フリーズ時にも本体〔I列〕に入力記録が残るようにしてあるので、本体を再起動すれば、たいていデータは残っている。ただし、「本文」欄はMS-Excelのテキストボックス・ツールなので「Esc」キーを押すのは禁物。保存前にキーを2度押すと、入力途中の全文が消えてしまう。
【Kanbun_Seikei.basの使い方】
〔準備〕ワードを起動し、ALT+F11キー(同時に押す。)で「VBエディタ」を起動する。「ファイル」-「インポート」を選び、このスクリプト・プログラムを選択する。あとは、この「マクロ」を実行すればよい。(下記参照。)ボタンやキーに割り当てれば使い勝手がよくなる。(割り当て方のマニュアルはWEBにいくらでも載っている。)
〔操作〕
はじめに、漢文エディタから書き出した本文をワードにおいて選択しておく。
①「マクロ」メニューから「Kanbun_Seikei」を選択して実行する。
②または、ボタンやキーに割り当てたこのマクロを実行する。

〔HTMLへの変換例〕

〔TeXへの変換例〕


〔MS-Wordでの表示-これはUnicodeの訓点で表示した例。色は指定可。〕

〔書き下し文の変換例〕 ※どの変換でも新旧両様の漢字で表記することができる。
(「データ操作」-「変換2」より、変換後のテキストを選択してから操作。)


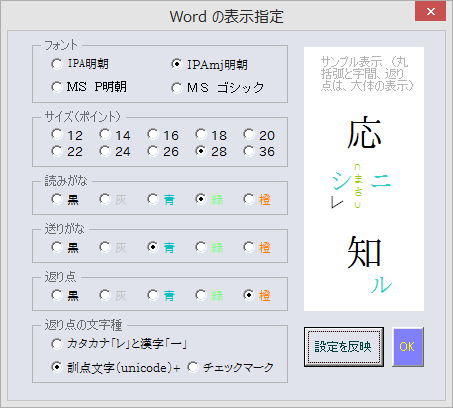
〔MS-Wordへの書き出し指定〕
【更新履歴】
◇スタイル・動作を多少スマートにした。文字実体参照へのエンコード・デコードの機能を付加した。書き下し文作成機能は、もう一度見直しをしている。(2012.3.28)◇書き下しボタンを一応使えるようにした。たまに触るだけなので、あまり大きな向上はない。一二点までの変換はだいぶしっかりしてきたが、まだ時々フリーズする。一二点を逆に入力するとほぼフリーズするので、登録時に記号をチェックする機能も付けたいが、だいぶ先の話である。項目名をカスタマイズできるようにした。エクセルの見出し項目(赤字)を変更するとフォームに反映する。ただし、見出しは必ず付ける。(5.19)◇「IE」ボタンを縦書きHTMLの簡単な書き出し用に改め、ついでにやや詳しい縦書きテンプレートの一例を上に掲げた。HTML用にタグ付けしたデータをこれにどんどん貼り付ければ、一通りの形はでき上がる。(5.26)◇「保存(訂正保存)」時にそのデータだけをcsv形式で日付フォルダに保存するようにした。(5.28)◇「そのデータ」だけのファイルを作るとムダに数が増えるので、日付のファイルにその日の作業分をまとめて追加するように改めた。(6.3)◇書き下し時におけるハイフンやルビの変換ミスを改めた。(12.28)◆上中下点の基本的な変換に対応した。文字実体参照への変換と復号ボタンは、各種変換タブの中だけにした。初めに変換してしまうと処理が煩雜になり、誤りが出てくるからである。(12.29)◇レ点の重なり、一レ点・上レ点、再読文字、而・如く・為り等の書き下し文変換を修正。(12.31, 2013.1.3)◇ユニコードにも入らない文字の扱いについて、「コード変換不可文字」ボタンを付けた。〓〝巾+軍〟のように、ゲタの後に解字説明を加える。+以外の記号によって解字説明を行った場合の各種変換に堪えかどうかは未検証だが、書き下し文ではゲタと解字部分が分離してしまう。これを直すのは、あちこちに影響が出て面倒になるので、解字部分を切り離してゲタのみで処理するようにしてある。(1.5)◆甲乙丙丁点の変換がいちおうできるようになった。天地人点にも対応するかと思うが、実際の例文にはまだ当たっていない。現在、「世説新語」の本文を入力・変換しながら検証している。書き下し文への変換を除いては、まず暴走する要素はないので、あらかた動くといってよい。問題は、「入力ミス」かもしれない。返り点の順番や組み合わせの種類を間違えて入力すると、記号が残ったままとなり、悪くすると暴走する。ハングしても、幸いWindows8からはスクリプトを《切り離す》という最悪のトラブルは起こさなくなったらしく、修正中何度もハングするがスクリプトは無事に保存されているように見える。これのおかげで、修正のスピードはよほど上がった。(1.6)◇天地人点も一応動くようだが、「書き下し文」の細かい調整を続けている。再読文字・上中下点・一二点の組み合わせ・ハイフンの繰り返し処理などだが、大幅に手を入れなければならないようなところはあまり見られなくなってきている。HTMLへのハイフン(竪点)の書き出しや変換タブ内のボタンの配置など、少し使い勝手を変更した。(1.14)◇上中下点の変換で暴走してしまったので修正した。(1.18)◇『漢文エディタ』においてエラーが出るのは「書き下し文」変換においてである。正規表現の*が影響している場合が多い。だいぶ修正し、再読文字に読み仮名をつけた場合・その否定形等の変換等に対応し始めた。例文を入力しながら実地に検証している。あらゆるパターンに対応するというわけにはいかないかもしれないが、実用度は十分なものと自負している。「書き下し文」変換を試みているのは、このアプリケーションが最初のものではないかと思う。なお、TaijuのWEBページに「漢文エディタ」の入力文そのものを轉載し、データの佚亡に備えている。このうち、Unicode専用字(環境依存文字)を変換したものは、Shift-JISのhtmlテキストファイルとしてブラウザに表示させるために、たとえば罄 ⇒ <span style="font-family: New Gulim;">罄</span> のようになる。このままでは「データ変換」タブからの各種変換がうまく機能しない。そこで先日消したボタンのうち、「データ入力」タブに「デコード」ボタンだけ戻した。これは、以上の理由により公開データの再利用時に限定して使うとよい。通常は「罄」を何とか入力したら、単語登録か何かで一時保存しておく。ユニコード専用字は「登録」時に必ずもう一度入力することになるので、その時に「?」の箇所に再度入力し、「訂正保存」する、という手順になる。(こういう操作はわりと多いので、機会があればヘルプファイルに載せておこうかと思う。)この種の不便は文字コード問題がすっかり解決するまでは我慢しなければならない。(1.19)◆デコードボタンを修正した。文字実体参照について、フォント指定付きの有無、10進・16進の区別を問わずにデコードする。文例ごとに細部の手直しは毎度のことである。(1.20)◇再読文字と上下点の組み合わせについて書き下し文を作れるようにした。文例に出合わないと気が付かない変換もまだあることだろう。(1.26)◆「再読文字」入力フォームを追加した。分りやすく、正確に入力できる。本文の途中への挿入も可能である。selstartのプロパティを使ってカーソル位置を求めることができた。(1.27)◆「簡易漢文エディタ」で作成したデータを取り込むタブを作った。ただし、数年前に簡単に作ったこのフォームにはハイフン(竪点)や注釈入力の機能がないので、そちらを先に修正すべきかもしれない。取り込み・変換と同時に登録を行うので、各種変換はすぐに使える。(1.30)◆タブ5に「簡易漢文エディタ」の大体を組み込んだ。「入-[二]力する漢文を[一]。」式に打ち込むこともできるようになった。注釈やルビにも対応する。難解な文字は、タブ1から打ち直して(デコードし)訂正保存することで変換可能である。その他、細かいことだが、範囲指定を多少間違えてもデコードを正確に行えるようにした。またWordのライブラリについての参照設定を外したので、Excelのバージョンが多少違っても起動するのではないかと思うが、確認はしていない。誤変換の訂正も相変わらず続けている。(2.3)◇「カナ」「かな」ボタンの修正、再読文字のルビ対応、ジャンプ時の「登録」ボタンの消去、ウィンドウ表示位置の変更、書誌事項の表示等、細かな変更を行った。書き下し文の検証も、実際の漢文を使って繰り返していくと、いろいろな発見がある。「容」が再読文字だということもこの検証過程で学んだことだ。「○[二]○○[一]○[レ]○[三]○-[二]○○[一]。」や再読文字が[一レ]点の位置に来る例など、言語の生きた形はさまざまである。(2.6)◇「漢文データ」シート上の「本文結合」ボタンを改善した。各種変換タブにルビと注釈の変換ボタンを加えた。「雖も」や「欲す」「思ふ」等を含めて「文・句」を受ける語の変換を工夫した。「○[二]○○[一]○[レ]○[三]○-[二]○○[一]。」も一応変換できる。検証のために入力している作品の文章も、すでに50章を超える。漢文エディタをとりあえずこの程度にbrush upするのに、主観的には3万ピース以上のパズルを作っていくような手間がかかっている。(2.9)◇入力本文から特定の文字列を拾い出す「検索」フレームを設けた。「かな」変換を一つにまとめた。細部のバグ取りを続けている。書き下し文としてのおかしな変換を見ると、入力文がまちがっていることに気づく。変換自体はずいぶんしっかりしてきた。(2.11)◇過去に入力した文を再度書き下し文に変換しながら確認している。再読文字・竪点と各種返り点との組み合わせや、レ点の反復回数の調整など、なすべきことはいくらでも出て来るが、調整した分だけ変換も逞しいものになるのが嬉しい。再読文字の左送り仮名やルビの挿入ボタンを付け加えた。Windows8でAtok8を使っているので、テキストボックスを選択するたびに半角モードのカナ変換という馬鹿げた状態になるのが腹立たしいくらいのものである。過去のAtokのユーザにも、入力モードの自動調整機能くらいは無償で対応させるのが○○だと思うのだが、ここに入れるべき言葉が思い浮かばない。そういう姿勢を表現することばが思い浮かばないのは、そういう発想ができなくなったということか。(2.17)◇再読文字の変換は文字の位置により調整が必要になる。書き下し文変換スクリプトをなるべく単純化してすっきりとさせたいと思うのだが。実用的なレベルにはもう達していると思うが、手直しの繰り返しである。(2.22)◆Wordのバージョンが異なっても(古くても)Wordへの書き出しができるようにした。WordのObjectLibrayへの参照設定を外し、「実行時バインディング」によって組み込むことがようやくできた。(3.20)◇Wordのメモリを解放していなかったのを改めた。なお、MS明朝などでは「・」となってしまう文字がある。Wordに書き出したUnicode文字を正しく表示するために、IPAmj明朝をインストールしておくとよい。(3.23)◆3.20の修正を行った後、改めてWordへの書き出しを行ってみた。「wd-」で始まるアトリビュートをすべてconstant(定数)に書き直したところ、すんなりとWordに書き出すことができた。これで、ようやく「漢文エディタ」単体でOffice連携ができるようになり、Excel2003以前にできていたことが改めて可能になったわけである。(3.30)◇訓読漢文への変換ボタンに「注記」を取り出して別記するボタンを加えた。ワードへの書き出し時に、多少便利か。但し、注記の位置に何かの記号を残しておく工夫が必要か。(3.31)◇ワードでの「ゝヽ」等の文字サイズ、一レ点の変換修正等。(6.11)◇再読文字の変換を調整。(6.16)◇上下点の変換を調整。(6.29)◇TeXへの変換部分が動かなくなっていたのを修正した。ヘルプに従って必要なファイルをインストールした後、EasyTeXのフォルダを指定しておく。スタイルファイルはデータ保存先に入れておくとよいようだ。また、注記の別記の書式、Replaceボタン、その他デザインを少々改良した。(12.31)
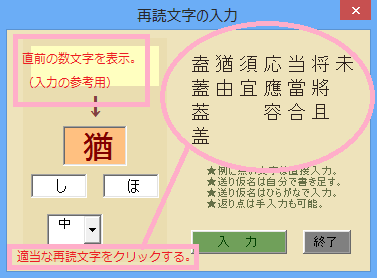
◆簡易漢文エディタからの入力項目に作品名・章節を加えた。また、現在のWindows8の環境では、Word2003以前のdoc形式では妙にフリーズすることが多くなったので、Word2007以降のdocx形式に改めた。その他、ルビタグの書き下し変換の手直しとUnicode文字実態参照ボタンの復活、注記の書き出し・HTML変換の修正、HTMLからの注記削除ボタンの付加等を行った。どれも微調整である。書き下し変換に「On Error Resume Next」指示を今さら加えたが、今のところ暴走せず、変換もスムースである。(2014.1.2)◇書き下し文の変換ミスをチェックする他、書き下し時の竪点と一二点の「照合」を書き下しの前に行う設定にした。うまく動くかどうか。(1.5)◆一二点の単純な「書き下し文」変換でも、現在の正規表現のスクリプトでは「限界」があるらしいことに気づいた。長い目的語だと倒置してくれないのだ。試してみたところ、70文字前後でハングアップしてしまう。VBAかRegExp5.5の限界なのか、単にスクリプトが練られていないのか。恐らく「(.+) 2\( (.+)) \)1 。」ならもっと長くてもよいのだろうが、漢字・ふりがな・送りがなのセット指定を反復しているため、入り組んだスクリプトと正規表現かVBAの一時メモリとの間でデータが溢れてしまうのだろう。今のところ、解決の見通しが立たない。Perlか何かを勉強するしかないだろうか。(1.12)◆ Progressに書いたが、上記の問題が偶然のことで解決した。理由は分からない。(1.14)◇再読文字や返り点をまたがる振り仮名の処理など、細部の調整をいくつか行った。(1.18)◇再読文字・使役形の変換の調整とTeXへの書き出しの修正等の微調整。(1.19)◇レ点の重なりに対応した。その他、再読文字の書き下し変換・打ち消し表現の整形の調整、注記の処理等。(2.3)◆レ点の重複、再読文字からさらに返読する場合、一二点のクロス形式、終尾詞処理、再読文字入力ウィンドウの記号変換修正等を行った。(2.17)◆