文字カウント等(WSH)
→画像
(クリックするとテキストファイルがそのまま表示されてしまうので、スクリプトそのものをダウンロードするには画像か圧縮ファイルの方をクリックする。)
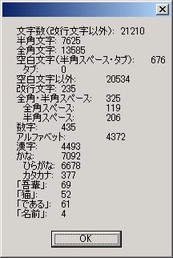
文字の種別によるカウントを行う。細かい調整はしていない。
【使い方】
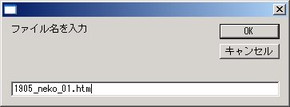
《Prof.1》「真魚」エディタ用である。任意のテキストを選び、「真魚」のメニューからスクリプトを実行する。「真魚」エディタでスクリプトを実行する方法は、「コマンド入力」(TJSoft-21)の項を参照。
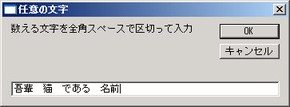
《Prof.2》「真魚」エディタに特化せず、一般に使えるスクリプトである。調べたいファイルのあるフォルダにスクリプトを置き、ダブルクリックする。ファイル名を拡張子を含めて入力し、続けて調べたい文字・語句を入力する。語句は複数入力することができる。
【改版履歴】
◇文字種別カウントを正規表現により行う。任意の文字・語句を入力することができる。初めてDictionaryオブジェクトを使ってみた。(2007.9.5)◇「真魚」エディタで部分文字列を対象とするときは、Ver.1(Prof.1)を使う。スクリプト単体で同様の機能を実現できるVer.2(Prof.2)を、これまでのスクリプトのやり方を使って作ってみた。Split関数のデリミタ(区切り文字)は既定値が半角スペースだが、全角スペースでもカンマでも、使いやすいものを指定できるので、その部分のスクリプトを変更してカスタマイズできる。ファイルも複数指定できるようにしようかと考えたが、あまり意味がないようにも思われた。ただし、別ファイルに書き出す形なら可能だろうと思う。(9.6)◇Prof.1の使い勝手をProf.2と同様にした。ただし、「真魚」エディタから使う。漢字コードを[一-龠]とした。ユニコードの並びは[亜-黑]ではなく、[一-龠]になっている。この使い分けの理屈が十分理解できていない。(9.8)
【余論】
かなの種類 -文字コード(Unicode)の不思議-
正規表現で「ひらがな」「カタカナ」「全角文字」「全角アルファベット」等の文字集合を書き表してProf.1やProf.2を作っていくうち、不思議な現象に気がついた。
たとえば、全角記号はあるWebページには[、-〇]で表せると書いてある。ちなみに、シフトJISの当該個所を抜き出すと次のようになる。
、。,.・:;?!゛゜´`¨^ ̄_ヽヾゝゞ〃仝々〆〇ー―‐/\~∥|…‥‘’“”()〔〕[]{}〈〉《》「」『』【】+-±×÷=≠<>≦≧∞∴♂♀°′″℃¥$¢£%#&*@§☆★○●◎◇◆□■△▲▽▼※〒→←↑↓〓∈∋⊆⊇⊂⊃∪∩∧∨¬⇒⇔∀∃∠⊥⌒∂∇≡≒≪≫√∽∝∵∫∬ʼn♯♭♪†‡¶◯
これについて、以下のように範囲を指定してカウントする。
[、-◯]
結果はこのようになる。これはProf.1タイプでもProf.2タイプでも同様である。範囲を変えていろいろやってみると、ハイフンによる範囲指定ができる場合とできない場合とがある。そこで、次にこんな範囲指定で試してみた。
全角記号 ―― [、。,.・:;?!゛゜´`¨^ ̄_ヽヾゝゞ〃仝々〆〇ー―‐/\~∥|…‥‘’“”()〔〕[]{}〈〉《》「」『』【】+-±×÷=≠<>≦≧∞∴♂♀°′″℃¥$¢£%#&*@§☆★○●◎◇◆□■△▲▽▼※〒→←↑↓〓∈∋⊆⊇⊂⊃∪∩∧∨¬⇒⇔∀∃∠⊥⌒∂∇≡≒≪≫√∽∝∵∫∬ʼn♯♭♪†‡¶◯]
全角アルファベット — [A-Za-z]
漢字(UNICODE) — [一~龠]
漢字 — [亜~黑]
第一水準 — [亜-腕]
第二水準 — [弌-熙]
IBM拡張 — [纊-黑]
かな — [ぁ-ヶ]
ひらがな — [ぁ-ん]
カタカナ — [ァ-ヶ]

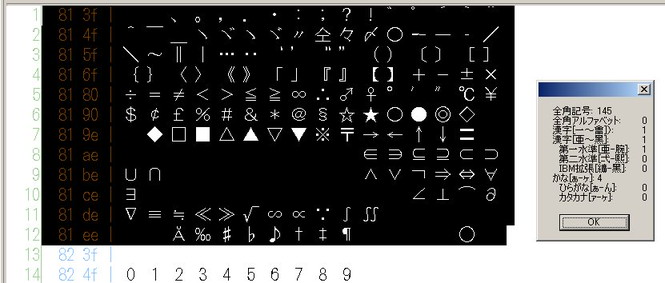
結果は右の図の通りである。記号が断続的に並んでいるのでハイフンによる範囲指定ではなく、文字をすべて「全角記号」として指定してカウントしたのだから、ヒット数は文字数に重なるわけで、これは当然かもしれない。しかし、「漢字」(第一水準)の「1」、および「かな」の「4」とは何か。(「ひらがな」0、「カタカナ」0であるにもかかわらず。)つまり、この一見記号の羅列の中には、漢字が1文字、平仮名でも片仮名でもない「かな」文字が4文字存在しているのだ。範囲指定を変えながら絞り込んでみた結果は、次のとおりである。
漢字 — 仝、かな — ゛゜ゝゞ

これについて説明(指摘)しているWebページがあった(「ひらがなやカタカナの取り扱い」
注1)。それによれば、Unicodeでは「ひらがな」と「カタカナ」とを比べると明らかにカタカナが多いが、カタカナにある小文字の「ヵ・ヶ」に対応するように小文字の「か・け」があること、カタカナには濁点を付したワ行文字や小文字があり、これに合わせるように「う゛」や予約領域があること、《長音記号》(これに《踊り字》〔躍り字・反復記号〕を加えてもよいだろう。)がそれぞれ「ひらがな」「カタカナ」の領域に割り当てられていること、そして恐らく予約領域の関係で(将来的に濁音文字を見出したときに対応できるように、か)《濁点》《半濁点》が独立して「かな」の項にコード化されているのだろう等々の推測が載っていた。(引用のまとめはTaiju式の素朴な文になっていることを断っておく。)恐らくそういう事情なのだろう、と納得できた。これだけすっきりと説明した文章が、他の「文字コード」の説明にあまり載っていないように見えた。このごろちょっと感じていることだが、概説的・公式的説明には長けていても、あまり自分で調べている感じをうけない文章が多いように見受けられるのは僻目か。スクリプトでも、こんな発想でやってみたという類が少なく、どれも似た感じがするのも気のせいか。
〔注1〕 http://www.exconn.net/Blogs/team01/archive/2005/12/20/5694.aspx

ついでのことに、図中に青丸・青四角で示したのは、Taijuが「合字・記号類」(TJSoft-19)でフォント化しようとした文字である。中には、ちょっと意味のわからない文字もあるが、ユニコードというものも相当丹念に集めたもので、一概に「似た字形を集めたもの」といって非難すべきではない。郵便記号と一緒くたなのは奇妙だし、必要のなさそうな文字も相当程度コード化されているが、なぜ日本人が先に部分的にでもコード化を提唱しておかなかったか。もちろん、Taiju氏もこれを今知ったくらいだから(ほんと何も知らねえなあ、でも知っている人はあまり啓蒙しねえよなあ、どこで澄ましこんでるんだろうねまったく)、まあ熊公八公が床屋で世の慨嘆をしている類なのである。
ともあれ、シフトJISの濁点・半濁点等をRegExpが「かな」に分類するのは、Unicodeの分類に基づくのだろう。図中にあるように、これによれば「ひらがな」は
[゛゜ゝゞぁ-ん]となり、「カタカナ」は
[・ーヽヾァ-ヶ]になり、「かな」全体では[・゛゜ヽヾゝゞーぁ-ヶ]ということになるのだろうか。同様に、拡張全角アルファベットはシフトJISの並びでいえば[`^_[]\A-Za-z]となるだろうか。(これらの記号はTaijuの例の試行錯誤の中で「全角アルファベット」に分類されたことがある。)これらはまだ確かめていない。(9.9)


Unicodeの並びで「ひらがな」「カタカナ」「全角アルファベット」を定義すれば、ハイフンで連続させる指定が可能である。シフトJISの文字の並びで同じ範囲を指定しようとすれば、飛び飛びに(連続した範囲は必ずコード順に)指定するしかない。それにしても、将来、「ひらがな」の指定を[ぁ-
け]とか[ぁ-ゞ]とか[ぁ-
=]などとするのも、釈然としないところが残るだろう。(「より」の合字があるのもやや古めかしいし、「こと」の合字や「可゛」、「まゐらせそろ(参候)」の略字等がその並びにないのも不統一な感じがする。「カタカナ」にしても[ァ-ヲ゛]とか[ァ-ヾ]、[ァ-┐]とかやってみても、「トキ」「トモ(ドモ)」の合字類は列からはみ出しているわけである。(ちなみに、Unicodeが標準でない現在の環境では、ここのサンプルも似た字形のもので代用しているに過ぎない。)全角アルファベットの配列についても、これらの記号がなぜここに配置されているのだろう。実用面でどう影響してくることになるのか不明だが、素朴に考えてUnicode標準のコンピュータ社会でも世界の文字の中で
日本の「ひらがな」はやはり「あ-ん」ですよと言いたくなるだろう。(小文字の「ぁ」も、なんのために必要なのだろう?)全角アルファベットは必要なものだろうか? 実際の使用例を追認しながら文字コードを割り振るのであれば、郵便局の記号や古典の合字・略字・記号やメール・チャットで必須かもしれない「ぁ」などはまとめて「暫定的記号類」に押し込めて、それらは必要な人のために専用の変換テーブルを画像形式と合わせてロゼッタストンのように保存しておき、半世紀に一度、書き換えてしまってもよいのではないか。「より」や「こと」「とも」の合字類を、そのまま後世に残す意味はほとんどないだろう。そもそも、欧米や日本をなんとなく真ん中に置いて(W3Cの構成メンバに寄り添うかのように)、次々とコードを割り当てるのはどんなものだろう。ジンバブエで日本のZip君の顔文字を使いたいと考えるだろうか。今は欧米の疾駆する馬の尻尾につかまった蠅のようにいいわいいわで過ごしていても、インドや中国の発言権が巨大化していき、やがて龍の顔文字や渦巻きのバリエーションが数十通り、ディーバナガリのローカル異体字が標準で何万と登録されていったら、そのとき日本人はその不公平を鳴らすことになるか? 等々と考えると、……(ああ、今日はなんだか調子がおかしいぞ。)たぶんなじんでいくのかな? 今つかまっている馬が谷底に墜ちたら、蠅だけ空に軽やかに舞い上がっていくか? (どこに飛んでいくの?)それに、時間的な軸で考えても、基本部分をまとめて配置しなおしてしまうと、現在Taijuが営々と古典の電子化を心がけても、Unicodeの改訂数版めにしてもう読めなくなってしまうのではなかろうか。コード割り当ての根幹が十数年ごとに変わってしまったりすることも分進秒歩のデジタルワールドではありえないことではない。そのときには、テキスト形式や画像さえも頼りになる保存形式ではなくなるかもしれない。古代の「竹」や「布」「木」や「石」などの、あるいは「紙」などのサブスタンシャルな(「物」としての)保存と並行させる以外にないのだろう。あるいは、そもそも長期の保存を当て込む必要がなく、テキストも軽やかに世の流れに従って漂っていけばよいという結論になるかもしれない。(9.9)
◇JIS X 0208の第一水準3,489字のうち、記号293字・英数字62字・かな169字・漢字2,965字という。同じくJIS X 0208の第二水準は、漢字3,388字(JIS X 0208-1990では3,390字)という。これを、シフトJISのコード表についてカウントの状況を見てみた。
①まず、記号類から。スクリプトでの範囲指定は上述の通りであり、「仝」ははじめから入れていない。この文字は「漢字」に分類されている。第一水準の[亜-腕]の指定でこれを拾っているのだが、もともとJIS X 0208が制定されたときには、これは《記号》(おそらく反復記号)だった。これは、下の図を見ても分かる。[亜-腕]の範囲2,965字には入っていないのである。念のため、これに続く「々」「〆」が漢字に入るかどうか見てみたが、これは相変わらず「記号」である。ちなみに、「々」は「仝」の略体、「〆」は「為」「貫目」「締・閉」等の略体かといわれる。「かな」を4つ拾っているのは、上述の「゛゜ゝゞ」である。(Unicodeでは「カタカナ」に分類されるはずの「・ーヽヾ」は拾っていない。)
②次に、アルファベット・かな・ギリシア(ギリシャ)文字48字・ロシア(キリル)文字66字・罫線文字32字を見てみる。全角文字のスクリプトでとりあえず範囲指定したのは「◯」までなので、当然この範囲からは1字も拾っていない。そこで、正規表現の範囲指定を順次行っていく。[0-9A-Za-zΑ-Ωα-ω]までは問題ない。ところがキリル文字は[А-Яа-я]の指定で数えると64文字になってしまう。調べてみると、「Ё」と「ё」を数えていないのである。アクセント記号の有無は他の文字にもあるが、どうしてこうなるのかはロシア語を知らないので分からない。罫線文字も同じく[─ - ╂](見やすくするため半角スペースを入れた。)では31文字しか拾わない。これは「╋」字をカウントしないためである。このような現象はあるが、一応の範囲指定は行える。この範囲の文字は計374字である。
[0-9A-Za-zΑ-Ωα-ωА-ЯЁа-яё─-╂╋]のようにすると377字を拾う。(コード順といいながら…А-ЯЁ…のような書き方ができる理由もまたよく分からない。|で区切ると見当はずれの字数を拾ってしまう。)カタカナはひらがなより「ヴヵヶ」の3文字だけ多い。

 moji_profile_1.lzh
moji_profile_1.lzh