
本例は<○○>のHTMLタグ取得で
ありテキスト文字はマッチしない
ので省略となっている。
| HTMLソースを変数に代入 |
Dim objIE As Object 'XMLHTTPオブジェクト
Dim dthtml As String 'htmlソース
Sub HTMLソース取得()
Dim fal As String 'ファイル種類
Dim objIE As Object
Dim urlk As String 'HTMLパス
'ファイル指定
'ファイル指定
fal = "HTMLファイル(*.html;*.htm),*.html;*.htm"
fff = Application.GetOpenFilename(fal, , Title:="HTMLファイル指定")
If fff = "False" Then
MsgBox "ファイルを指定して下さい"
Exit Sub
End If
'過去データ削除
Worksheets("Sheet1").Select
Cells.ClearContents
Range("A1").Select
Set oHttp = CreateObject("Microsoft.XMLHTTP")
oHttp.Open "GET", urlk, False
oHttp.Send
dthtml = StrConv(oHttp.responsebody, vbUnicode)
Call 正規標記確認
End Sub
|
| 正規標記で検索オブジェクト |
Sub 正規標記確認()
Dim oReg As Object
Dim itmsu As Integer
Dim tst As String
Set oReg = CreateObject("VBScript.RegExp") 'VBScript.RegExpオブジェクトをセット
oReg.Pattern = "<[^<>]+?>" ' 表示文字列のマッチパターンを取得します
oReg.Global = True ' 全体を対象とする
itmsu = oReg.Execute(dthtml).Count '下記MatchesのMatcheオブジェクト(Item)数
With oReg.Execute(dthtml) 'Executeは成功したマッチの Matchesコレクション オブジェクト
For j = 0 To itmsu - 1 '0スタートであり個数は-1する
Cells(j + 2, 1) = .Item(j) '取得したMatcheオブジェクトをシートへ表示
Next
End With
Set oReg = Nothing ’oRegオブジェクト終了
Set oHttp = Nothing ’oHttpブジェクト終了
End Sub
|
| 正規標記確認を実行結果 |
|
本例は<○○>のHTMLタグ取得で ありテキスト文字はマッチしない ので省略となっている。 |
| HTMLソース |
Sub 正規標記確認()
Dim oReg As Object
Dim itmsu As Integer
Dim tst As String
Set oReg = CreateObject("VBScript.RegExp")
oReg.Pattern = ">[^<>]+<"
oReg.Global = True
itmsu = oReg.Execute(dthtml).Count
With oReg.Execute(dthtml)
For j = 0 To itmsu - 1
Cells(j + 1, 1) = .Item(j)
Next j
End With
Set oReg = Nothing
Set oHttp = Nothing
End Sub
|
| 正規標記確認を実行結果 |

本例は">""<"もマッチ対象なので ">""<"も抽出します。 |
| HTMLソース |
Sub 正規標記確認()
Dim oReg As Object
Dim itmsu As Integer
Dim tst As String
Set oReg = CreateObject("VBScript.RegExp")
oReg.Pattern = ">([^\s<>]+)+?<"
oReg.Global = True
itmsu = oReg.Execute(dthtml).Count
With oReg.Execute(dthtml)
For j = 0 To itmsu - 1
Cells(j + 1, 1) = .Item(j).SubMatches(0) '()でククッタ箇所取り出し
Next j
End With
Set oReg = Nothing
Set oHttp = Nothing
End Sub
|
| 正規標記確認を実行結果 |
|
| 正規標記で検索プロシージャ |
Sub 正規標記確認() '←6項のHTMLソース取得()プロシージャから呼び出し
Dim oReg As Object
Dim itmsu As Integer
Dim tst As String
Set oReg = CreateObject("VBScript.RegExp") 'VBScript.RegExpオブジェクトをセット
oReg.Pattern = "<a hrefa href=[^>].+?</a>" '(表示上&lt;記述であり半角<に直すこと)
oReg.Global = True 'oRegオブジェクト全体を対象とする
itmsu = oReg.Execute(dthtml).Count '下記MatchesのMatcheオブジェクト(Item)数
With oReg.Execute(dthtml)'Executeは成功したマッチの Matchesコレクション オブジェクト
For j = 0 To itmsu - 1
Cells(j + 1, 1) = .Item(j) '取得したMatcheオブジェクトをシートへ表示
Next j
End With
Set oReg = Nothing ’oRegオブジェクト終了
Set oHttp = Nothing ’oHttpオブジェクト終了
End Sub
|
| 正規標記確認を実行結果 |
|
文字がないので抽出されない |
| 正規標記で検索プロシージャ |
Sub 正規標記確認() '←6項のHTMLソース取得()プロシージャから呼び出し
Dim oReg As Object
Dim itmsu As Integer
Dim tst As String
Set oReg = CreateObject("VBScript.RegExp")
oReg.Pattern = "(?:href|src).+?>"
oReg.Global = True
itmsu = oReg.Execute(dthtml).Count
With oReg.Execute(dthtml)
For j = 0 To itmsu - 1
Cells(j + 1, 1) = .Item(j)
Next j
End With
Set oReg = Nothing
Set oHttp = Nothing
End Sub
|
| 正規標記確認を実行結果 |

|
| 正規標記で検索プロシージャ |
Sub 正規標記確認()
Dim oReg As Object
Dim itmsu As Integer
Dim tst As String
Set oReg = CreateObject("VBScript.RegExp")
oReg.Pattern = "href[^>]+>(.+?)?</a>"
oReg.Global = True
itmsu = oReg.Execute(dthtml).Count
With oReg.Execute(dthtml)
For j = 0 To itmsu - 1
Cells(j + 1, 1) = .Item(j).SubMatches(0) 'テキストを捕捉グループで取得
Next j
End With
Set oReg = Nothing
Set oHttp = Nothing
End Sub
|
| 正規標記確認を実行結果 |

|
| 正規標記で検索プロシージャ |
Sub 正規標記確認() '←6項のHTMLソース取得()プロシージャから呼び出し
Dim oReg As Object
Dim itmsu As Integer
Dim tst As String
Set oReg = CreateObject("VBScript.RegExp")
oReg.Pattern = "<table[^>]+>"
oReg.Global = True
oReg.IgnoreCase = True '大文字小文字を区別しない
ken1 = oReg.Execute(dthtml).Item(0).FirstIndex '<tableの文字位置取得
oReg.Pattern = "</table>"
ken2 = oReg.Execute(dthtml).Item(0).FirstIndex '</table>の文字位置取得
dthtml2 = Mid(dthtml, ken1, ken2 - ken1) 'テーブル内の文字を変数dthtml2へ代入
oReg.Pattern = ">([^\s<>]+)+?<" '">?<間のパターン設定
itmsu = oReg.Execute(dthtml2).Count '下記MatchesのMatcheオブジェクト(Item)数
ra = 1: ca = 1
With oReg.Execute(dthtml2)
For j = 0 To itmsu - 1
Cells(ra, ca) = .Item(j).SubMatches(0) 'Matcheオブジェクトをシートへ表示
ca = ca + 1
If ca > 10 Then
ra = ra + 1: ca = 1 'セルの行列補正
End If
Next j
End With
Set oReg = Nothing
Set oHttp = Nothing
End Sub
|
| 正規標記確認を実行結果 |
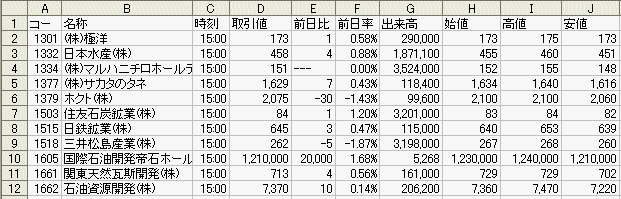
|
| 正規標記で検索プロシージャ |
Sub 正規標記確認() '←6項のHTMLソース取得()プロシージャから呼び出し
Dim oReg As Object
Dim itmsu As Integer
Dim tst As String
Set oReg = CreateObject("VBScript.RegExp")
oReg.Pattern = "<meta(.+)?>"
oReg.Global = True
oReg.IgnoreCase = True
itmsu = oReg.Execute(dthtml).Count
With oReg.Execute(dthtml)
For j = 0 To itmsu - 1
Cells(j + 1, 1) = .Item(j).SubMatches(0)
Next
End With
Set oReg = Nothing
Set oHttp = Nothing
End Sub
|
| 正規標記確認を実行結果 |

|
| 正規標記で検索プロシージャ |
Sub 正規標記確認() '←6項のHTMLソース取得()プロシージャから呼び出し
Dim oReg As Object
Dim itmsu As Integer
Dim tst As String
Set oReg = CreateObject("VBScript.RegExp")
oReg.Pattern = "<!(?:--)([^<>]+).+?(?:-)>"
oReg.Global = True
oReg.IgnoreCase = True
itmsu = oReg.Execute(dthtml).Count
With oReg.Execute(dthtml)
For j = 0 To itmsu - 1
Cells(j + 1, 1) = .Item(j).SubMatches(0)
Next
End With
Set oReg = Nothing
Set oHttp = Nothing
End Sub
|
| 正規標記確認を実行結果 |
|
|
| 正規標記で検索プロシージャ |
Sub 正規標記確認() '←6項のHTMLソース取得()プロシージャから呼び出し
Dim oReg As Object
Dim itmsu As Integer
Set oReg = CreateObject("VBScript.RegExp")
oReg.Pattern = "(\w+)@(\w+)\.(\w+)"
oReg.Global = True
oReg.IgnoreCase = True
itmsu = oReg.Execute(dthtml).Count
With oReg.Execute(dthtml)
For j = 0 To itmsu - 1
Cells(j + 1, 1) = .Item(j)
Next
End With
Set oReg = Nothing
Set oHttp = Nothing
End Sub
|
| 正規標記確認を実行結果 |
|
|
| 正規標記で検索プロシージャ |
Sub 正規標記確認() '←6項のHTMLソース取得()プロシージャから呼び出し
Dim oReg As Object
Dim itmsu As Integer
Set oReg = CreateObject("VBScript.RegExp")
oReg.Pattern = "\d+/\d+/\d+"
oReg.Global = True
oReg.IgnoreCase = True
itmsu = oReg.Execute(dthtml).Count
With oReg.Execute(dthtml)
For j = 0 To itmsu - 1
Cells(j + 1, 1) = .Item(j)
Next
End With
Set oReg = Nothing
Set oHttp = Nothing
End Sub
|
| 正規標記確認を実行結果 |
|
|